




In the past year, I had the opportunity to drive a greenfield project to create a brand new Spectro Cloud product, PaletteAI. One of the early decisions the team made was to use a monorepo: a single repository containing the whole codebase.
While I recognize there are pros and cons to different repository architecture strategies — and this guide from GitHub does a good job of articulating them — I have a confession: traditionally, I’m a polyrepo guy. I simply prefer isolated codebases with a single, clear purpose (think UNIX philosophy: do one thing well).
After the launch, I was reflecting on the journey the team and I went through over the past year. One thing that stood out to me was that choosing a monorepo provided some surprising benefits when integrating Artificial Intelligence (AI) tooling into our development workflows and development pipeline (CI/CD).
In fact, I’ve changed my mind: I now believe monorepos have a clear advantage for future development workflows. Let me explain why.
So how did we set up the repo?
Our monorepo contains several microservices, a user interface (UI), and a docs site. You can think of this as a native Kubernetes application, as the microservices are all Kubernetes controllers. While I’ve left out some other Go packages and miscellaneous bits, imagine our repo looks something similar to the following folder structure:
.
├── service-a
├── service-b
├── service-c
├── service-d
├── service-e
├── docs
├── shared-ui-code
├── shared-go-code
├── go.work
├── go.work.sum
├── apis
├── helm-chart
├── CODEOWNERS
├── helm-crdsAccess control follows the traditional GitHub OWNERSFILE approach, where different folders can have permissions assigned to different teams.
Automating code reviews
Here at Spectro our product quality and security are absolutely critical, and we have initiatives running across our engineering organizations to drive continuous improvement.
One simple step to take is catching issues or potential issues in the review process, and like many other development teams, we have enabled automatic code reviews through AI tooling whenever an engineer creates a pull request.
There are plenty of tools out there, each with their strengths and weaknesses; we settled on using CodeRabbit for our automated reviews. Of course, it’s not perfect, but it has found several potential bugs that might have slipped past a human reviewer — and as such, it has definitely delivered benefits.
So how does this relate to the monorepo architecture?
Automated code reviews use the pull request's context, including the files modified, added, or deleted, to identify discrepancies. Due to the nature of the monorepo, these changes may be tackled in one pull request (if it makes sense, otherwise, a feature branch works too), and in that event, having the context of the different folders can set you up for some nice scenarios where issues are caught that a human reviewer may miss.
Take the following example. In the pull request below, the application was updated to read Kubernetes secrets. The non-admin user roles do not have access to the secrets resource, so the correct answer is to use the system service account to retrieve these secrets in this scenario. It’s an easy mistake to make, but because of other related changes in the same change set, the code review tool correctly flagged the issue. Had the backend and the UI been in separate repositories, this mistake could potentially have slipped through.
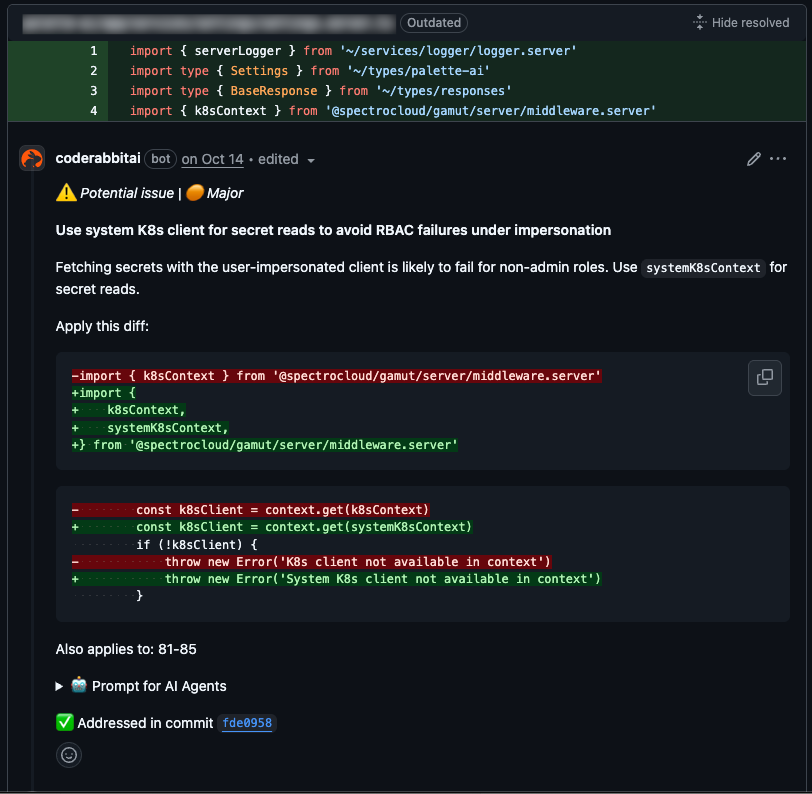
Feeding models full context during development
When AI model providers release new model versions, they often increase the supported model context window. For example, Claude has expanded from 200k tokens to 1 million tokens over the past year.
This is a boon for software developers using coding assistants such as Cursor or Claude Code: with a bigger context window, we can give the model more context about our codebase, and hopefully get better output.
In a monorepo setting, I can quickly add the entire context of a few services when researching a code change or refactoring logic.
Tools like Cursor and VS Code can add multiple repositories to a Workspace and still index their content, so the difference between a monorepo and separate repositories is minimal. The real benefit is the ability to review all the changes in a single pane, which yields benefits like the example shared above with the RBAC mistake in the UI.
Agentic workflows are becoming increasingly common. Agentic workflows need reliable context and predictable project structure. Open standards like AGENTS.md are explicitly intended to provide “project-specific instructions and context” to agents. A monorepo can make that simpler: one canonical set of agent instructions and conventions at the top level, with clear subdirectories, ownership, and intent.
Standards and protocols are maturing, as evidenced by the latest formation of the Agentic AI Foundation (AAIF). The AAIF is the stewards Model Context Protocol (MCP), agents.md, and Goose. As a proud supporting member of the AAIF, we expect more maturity in this space.
Automatic documentation generation
As any enterprise software user knows, an application is only as good as its documentation. Docs are the key to getting up and running, mastering new features, and troubleshooting problems. But many organizations struggle to invest enough in their docs teams: writing and maintaining clear, accurate and comprehensive documentation is time-consuming and challenging work (I should know… I used to run our docs team here at Spectro!)
AI of course can enhance how you maintain your documentation. And when using monorepos that consolidate documentation alongside code, the readily available, localized context results in documentation updates that are more accurate and pertinent.
In the world of technical writing, new product features and significant updates are usually identified and properly documented. What has the highest risk of being missed and not getting documented are the small changes. Think of situations such as changing a field’s value from 3 to 1. Depending on what the impact is, the value change could have a significant effect on the end user. It’s these types of changes that I am thrilled to get AI to help us catch and identify. Tools like Mintlify and Dosu both focus on automatically updating documentation knowledgebases by reviewing the changes introduced in a pull request.
Below is a screenshot of a pull request in which Dosu identified three items in the knowledge base that need updating.
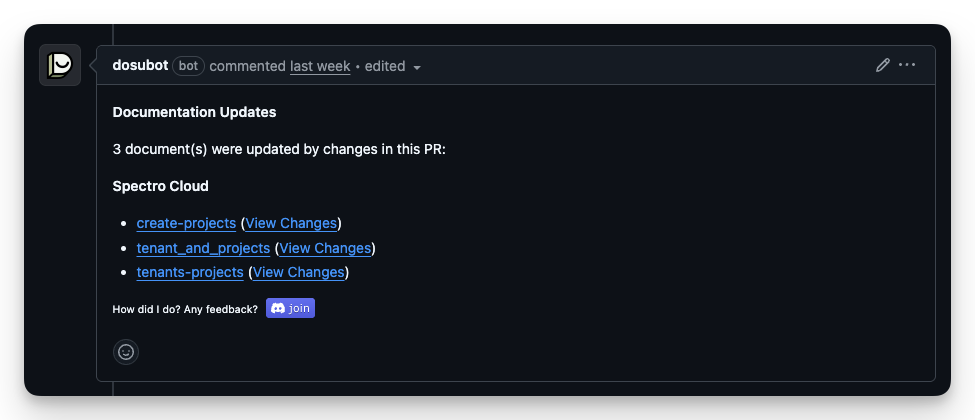
We are still experimenting with these types of automatic documentation change workflows, but it’s exciting to see the potential.
Answering internal questions
Have you ever wondered whether a feature was merged into the codebase? Or when a bug fix was addressed? Or what has changed in the code since a specific date?
Most teams use a combination of a ticketing system and their version control systems' pull request and merge request features to hunt this down. Sometimes the answer may be in Slack or another source, like a Confluence page. The point is that finding the answer to an internal question can be a chore, which results in you probably interrupting a colleague or firing a desperate question into a public channel.
This is where modern data integration tools that act as assistants can add significant value. Tools like Super, which we have connected to various internal data sources, can cross-reference information to help us answer simple questions like the ones above.
The benefit of a monorepo is that it's easier for these data tools to find answers when reviewing pull requests/merge requests, issues, Jira tickets, Slack, and so on, because all services and relevant code changes are housed in the same location.
By not having to traverse different repositories, it reduces the steps needed to gather the information needed to answer the question. You can, of course, do this with multiple repositories, but the complexity increases … and when it comes to AI tooling, the fewer steps, the better.
So: monorepo or polyrepo?
The correct answer is what makes the most sense for you and your team! I know, it’s no fun to be uncontroversial, but that’s also not the point of this article. There are neat benefits that lend themselves to AI workflows in the context of a monorepo worth considering if you and your team are evaluating versioning control setup architecture.
One question we have is, will these benefits still be available as the repository grows? Are these benefits possible in a large monorepo, or is the context window still a limiting factor? The good news is that with each model release, context windows grow, as does the model's capabilities.
Next steps
We’re exploring agentic development workflows as part of our work in the open-source community and AAIF membership. We also encourage you to check out some of our newer public repositories, such as the palette-sdk-typescript, where we are experimenting and leveraging agentic capabilities and AI tooling. Lastly, if you want to learn more about PaletteAI, our latest product that is enabling AI developers, check out https://www.palette-ai.com/.