



.jpg)
Edge AI is a recurring theme across our work in the healthcare sector, particularly with medical equipment manufacturers. Dentsply Sirona uses AI as part of its intraoral scanning platform, running in thousands of dental offices. RapidAI uses a mix of edge and cloud compute to power its AI stroke diagnosis product. These are far from isolated examples.
Bringing AI to the edge — whether it’s the patient bedside, the operating room, the nurse’s station, or the clinician’s desk — promises to unlock a diverse set of positive outcomes through faster, more accurate decision-making.
In our State of Edge AI research, 72% of respondents said they could already confidently demonstrate the business value of edge AI if their CEO asked about it today.
But edge AI also introduces a host of operational, regulatory, and security challenges that medical device manufacturers must overcome before care providers can adopt their edge AI powered solutions with confidence.
How AI at the edge elevates patient care
Of course, AI is already being applied across healthcare operations and clinical workflows at massive scale in the data center and the cloud.
Providers are using it to optimize forecasting bed demand, ED surges, and staffing needs; to extract structured data from messy EHR notes for population health and quality reporting; in centralized radiology and digital pathology AI services that support network-wide triage and workload prioritization.
You see it in predictive risk models that flag patients for care management, in revenue cycle intelligence that tightens coding and documentation, and in patient engagement copilots that handle scheduling, portal questions, and call-center routing across millions of interactions.
But for all that breadth and scale, it’s the edge use cases — AI embedded into the moments and places where care is delivered — that tend to have the most viscerally felt, immediate impact on patient outcomes and on the day-to-day experience of clinicians and caregivers.
Real-time intelligence delivered locally allows responses to patient conditions as they unfold, including adjustments during procedures and just-in-time interventions.
Examples include:
- Continuous monitoring that can identify subtle deterioration trends before alarms would normally trigger
- Computer-vision-aided surgical procedures in which AI provides continuous guidance or warnings based on live data streams
- Smart infusion systems that can adjust dosing based on real-time patient response
- Ventilation or respiratory support systems that can adapt to changing physiology.
Instead of adding more automated alerts to the cacophony that frontline staff already have to endure, AI can filter, prioritize, and contextualize information and deliver summarized insights instead of raw data streams. On-device triage in emergency or ambulance settings can guide routing or treatment decisions. Rapid bedside analysis can reduce time to intervention in critical care scenarios.
The ‘edge’ is as important as the ‘AI’
Across all of these use cases, the edge computing model is a critical part of their feasibility. Only with the AI model actually running in proximity to the care situation can you:
- Deliver a near real time response to data, without the latency of a round-trip to the cloud or data center for analysis.
- Provide functionality in places where connectivity is limited or unpredictable, such as rural or underserved areas, in patient homes, and in mobile care units.
- Scale without bottlenecks: imagine the bandwidth requirements if thousands of devices across a care facility all needed to communicate continuously back to the cloud simultaneously — particularly if they’re sharing intensive data like video.
The overarching principle is simple: When decisions can be made locally, in real time and reliably, care changes for the better.
Not just local — autonomous
A local-first architectural design is, as we’ve just explored, essential for many edge AI applications in healthcare, but we actually need to go even further and assume that network connectivity may not be available at all, even for edge device management and other ‘back end’ functionality.
In our State of Edge AI research, 81% of our respondents said that at least
some of their deployed devices are in offline, disconnected or air-gapped mode.
Network outages and other disruptions are unfortunately a fact of life in healthcare environments, even leaving aside rural, mobile and other more temperamental locations. Care-critical applications need to continue operating even when:
- Cloud connectivity is degraded or unavailable
- Central management systems can’t be reached
- Updates are delayed for days or weeks
- Telemetry is incomplete or buffered locally
These disruptive circumstances complicate everything from monitoring and alerting to policy enforcement and incident response. Designs that assume constant connectivity often work in demos or in ideal deployment sites, but fail in production in the real world.
The design requirements should be founded on autonomous operation. That means local enforcement of policy, and periodic, opportunistic reconciliation with central systems rather than real-time dependency on them.
Beyond assured availability: trust and guardrails
Medical devices operate in environments where failures aren’t just inconvenient; they can directly impact patient safety.
If an AI-assisted monitoring system misses a critical signal, if a device becomes unresponsive during a procedure, or if an update disrupts a workflow at the wrong moment, the consequences can be life threatening.
That reality changes how edge systems must be designed, tested, and operated. Being “rock solid” at the edge means assuming things will go wrong and designing systems that remain safe and predictable when they do.
Software and lifecycle failures in medical devices are far from hypothetical. Regulators have issued major recalls where software defects, unsafe configurations, or insufficient update controls created patient risk. Historically, incidents like the Therac-25 radiation therapy overdoses showed how software behavior can directly harm patients. More recently, infusion pumps and patient monitoring systems have repeatedly been recalled for software issues, including defects that could interrupt therapy or display incorrect information.
The point is not that edge AI is uniquely dangerous, but that device makers must continue to treat software change control and field performance as safety-critical disciplines.
This is especially challenging because AI models at the edge typically don’t fail in one dramatic way. They often fail in ways that are hard to detect until outcomes are affected. Model drift is one common issue: models are trained on historical data, but real-world conditions change.
But drift is only part of the model-risk picture. Edge AI can also degrade when inputs are out of distribution (new scanner settings, different patient populations, lighting or sensor changes, new clinical protocols), when uncertainty isn’t surfaced (the model keeps predicting confidently when it shouldn’t), or when downstream workflows amplify small errors. Human factors matter too: automation bias, alert fatigue, and UI changes can turn a modest model error into a real clinical risk. That’s why operational monitoring needs to include model quality signals, not just system uptime.
In many cases, the root is poor control over software behavior in complex environments. As the scale increases and devices become more connected and intelligent, the risk radius of these failures increases.
A fleet-management mindset
The defining attribute of edge deployments is distributed scale. Customers of ours like GE HealthCare, RapidAI and Dentsply Sirona are routinely talking about managing thousands of devices across customer sites.
Hundreds or thousands of devices need to behave consistently, even though they’re deployed in different hospitals, clinics, ambulances, and homes. Each device may experience different network conditions, hardware constraints, and usage patterns. To ensure that all of these thousands of devices behave predictably, safely and securely, your operations teams need to adopt a rigorous fleet management mindset from the very start of the project.
At fleet scale, automation becomes mandatory across the entire lifecycle: design, provisioning, patching, monitoring, securing, and decommissioning. Anything that requires hands-on work per device will not survive at scale. If your edge AI strategy can’t be managed as a fleet, it isn’t production ready.
Adopting a fleet mindset at the edge means:
- Zero-touch or low-touch provisioning, for faster, less error-prone and less costly deployments to distributed locations.
- Consistent configuration and policy with centralized visibility across sites, for assurance of system health, compliance, SLAs and alerting for fast troubleshooting.
- Automated lifecycle management, because edge devices are not static assets. Over time, they’ll experience hardware degradation, software updates and configuration changes. Configuration drift can be solved.
- Minimal reliance on on-site intervention, because a clinical site is unlikely to have the right expertise at hand, and a field engineering visit means a costly truck roll.
When thousands of devices behave differently because of configuration drift, manual interventions, or inconsistent updates, risk increases. Rock-solid systems are standardized systems that are deployed the same way, managed the same way, and governed under the same rules across the entire fleet.
Failures must be contained and observable. When something goes wrong at the edge, it should fail in a known, safe way and should be detectable. That means health checks, redundancy where appropriate, clear alerting, and the ability to diagnose issues remotely without interrupting clinical use.
Edge AI adopters know that the key to success is the ability to deliver consistently at scale. In fact, in our State of Edge AI research, respondents ranked ‘consistent and standardized deployments’ as the second most critical capability, after security.

Edge device and AI model: the two sides of lifecycle management at the edge
In reality, AI at the edge has two overlapping but distinct lifecycles to manage: the edge-device lifecycle and AI-model lifecycle. Medical device manufacturers must manage both lifecycles continuously and safely.
The device lifecycle is about the physical and software system that delivers care. This lifecycle is governed by traditional medical device requirements: FDA design controls and Quality System expectations (or ISO 13485 in many global programs), ISO 14971 risk management, software lifecycle controls (often aligned to IEC 62304), cybersecurity obligations, and post-market surveillance. Changes here are high-impact events because they can affect device behavior, clinical workflows, and the evidence you rely on for safety and effectiveness.
Running in parallel is the AI-model lifecycle, which moves at a very different pace. AI models evolve faster than hardware or core software. They’re trained, validated, deployed, monitored, refined, and sometimes retired, often multiple times over a device’s lifetime.
Take a look at this data from our State of Edge AI report. Do you have the operational excellence to ship new models to end users every month?
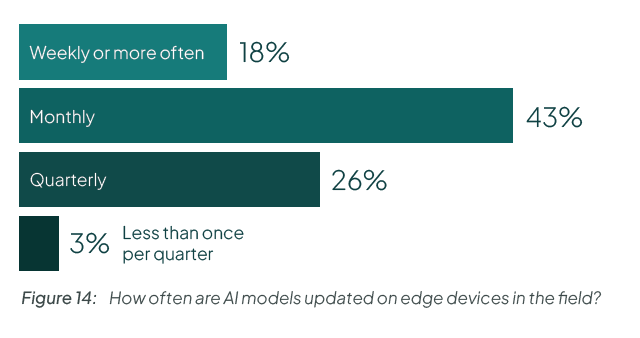
Compounding the difficulty is that these two lifecycles are tightly coupled. A model update may depend on a specific runtime version. A platform update may change GPU drivers or inference behavior. A security patch may affect performance characteristics. Treating device updates and model updates independently creates risk.
Automation across the edge-device lifecycle
For the edge-device lifecycle, the goal is to ensure that every edge device software stack is compliant with the configuration that was validated and approved compliant.
You can achieve this by creating a profile that captures the entire desired state of the system, from its OS and software components down to the image version, to its configuration. Using a declarative management pattern with reconciliation loops, you can monitor for deviations away from the known-good state, and correct them automatically.
Another key principle that can help is immutability: the concept that the software image on the device cannot be changed at all, it’s effectively read-only apart from certain user directories. By building the device’s software payload as an immutable, bootable atomic image through a centralized pipeline, you know that there won’t be any changes, updates or additions made on the device itself. When you need to make a patch or upgrade, you build an entirely new image, flash that to a second partition on the edge device and reboot over to the new version. If for some reason the flashing process has failed, you can failover to the old version and try again. Either way, you know that only an approved image is being used.
Automation across the AI-model lifecycle
Managing AI safely at the edge means treating models and software as regulated, evolving assets. That starts with immutable, versioned artifacts. Every software build and every model must be uniquely identifiable, signed, and reproducible. You also need supply-chain evidence: SBOMs for software dependencies, provenance for container images, and clear lineage for models (training data versions, evaluation sets, and release criteria). This makes it possible to know exactly what is running on each device and to reason about risk when something changes.
Equally important is continuous observability. Manufacturers need visibility into both system health and model behavior: performance metrics, error rates, resource usage, and leading indicators of model-quality issues (drift signals, out-of-distribution detection, calibration/uncertainty metrics). Because connectivity isn’t guaranteed, observability must include local buffering and eventual synchronization, not just real-time dashboards.
Data security risk increases as the edge footprint grows
Edge deployments fundamentally change the security equation for medical devices, and AI raises the stakes even further.
AI at the edge expands the attack surface in several ways. Unlike centralized systems, edge devices are often physically accessible and deployed in semi-controlled environments such as hospitals, clinics, ambulances, or patient homes. Networks are segmented or outside the manufacturer’s control, software is distributed across large fleets, and connectivity is often unreliable. AI adds an additional layer of risk: models, inference pipelines, and data flows now directly influence clinical behavior.
Detecting and responding to compromises is especially difficult at the edge. Remote sites often lack IT staff, devices may be offline when incidents occur, and telemetry may arrive late or incomplete. Effective security therefore depends on strong device identity, continuous monitoring of system behavior, local integrity checks that work offline, and centralized correlation when connectivity returns.
This is why “zero trust” is useful shorthand at the edge — but it only matters if it shows up as concrete controls. Devices need strong identity (device certificates, attestation where feasible), least-privilege access, and network segmentation. Boot chains and runtime components should be protected with secure boot and integrity checks. Updates and model packages must be signed and verified; secrets and certificates must be rotatable; and every access path must be auditable. On top of that, manufacturers need an SBOM-driven vulnerability process, a coordinated vulnerability disclosure program, and patch/rollback mechanisms that work even when sites are intermittently connected.
Security at the edge is also a lifecycle discipline. Manufacturers must continuously track vulnerabilities, correlate security events with device and AI behavior, respond remotely at fleet scale, and generate evidence for regulators and auditors. That evidence includes update histories, configuration baselines, access logs, and proof that critical controls (encryption, signing, integrity checks) are actually enforced in the field.
The bottom line: strong identity, signed and reversible updates, encrypted storage and transport, SBOM-backed vulnerability management, and continuous monitoring are the baseline for deploying AI responsibly when lives are at stake.
The regulatory reality you can’t ignore
In the U.S., the FDA regulates software functions that influence safety and effectiveness whether they are embedded in a physical device or delivered as standalone software (SaMD). The key expectation is lifecycle control: manufacturers must show not only that a device works at launch, but that it continues to operate safely as software and models change over time. For devices that meet FDA’s definition of a “cyber device,” Section 524B makes premarket cybersecurity content and ongoing vulnerability management explicit obligations, including secure update and patch processes. And for AI-enabled device software functions, the FDA’s Predetermined Change Control Plan (PCCP) approach is designed to let manufacturers plan bounded model changes with documented methods and monitoring, reducing uncertainty about how iterative improvements can be managed under a controlled framework.
Device manufacturers operating internationally also need to align with risk management and quality frameworks such as ISO 14971 and ISO 13485, and meet regional regulatory expectations (for example EU MDR/IVDR and UK MHRA guidance) for medical device software and AI-enabled functions. In the EU, AI rules are also evolving, and device makers should expect increasing focus on risk management and transparency for high-risk AI use cases alongside MDR/IVDR obligations. The regulatory details vary, but the operational requirement is consistent: you need traceability, controlled change, and evidence generation across the full lifecycle.
Maintaining compliance at the AI edge requires operational discipline that spans safety, security, and performance. Manufacturers must be able to track exactly what software and models are running where, stage and control updates, monitor behavior in the field, and respond quickly to issues through QMS processes such as CAPA and post-market surveillance.
ISO 14971-style risk management and quality processes must be backed by real operational capabilities: audit-ready evidence, secure and reversible update mechanisms, validated deployment boundaries, and the ability to roll back changes safely. In practice, ongoing compliance requires infrastructure that enforces consistency, traceability, and controlled change across the entire device fleet — not just at release, but every day the device is in use.
Challenging? Sure. But edge AI is worth doing
After all that, it’s clear that edge AI projects have a lot of thorny problems to solve, from how to handle disconnected operations, to assuring security and compliance.
Here at Spectro Cloud we can’t promise to solve every one of those challenges for you — but we can offer you a robust foundation for your edge AI initiatives. With our Palette management platform we enable you to build trusted software stacks, from OS to model, and deploy them consistently to your edge devices. Once deployed, we keep the device running in line with policy and give you capabilities to secure and update them.
We’ve been doing edge for years, so our platform is mature and handles all the unique challenges of edge: from boot-tampering attacks, to network outages and headless device onboarding.
Importantly, we’ve also been doing this for healthcare manufacturers for years — companies like GE HealthCare, RapidAI and Dentsply Sirona.
So if you’re working on your edge AI initiatives, come talk to us and see how we can help.