




From RAGs to riches
Retrieval-Augmented Generation (RAG) is one of the most practical patterns in enterprise AI settings right now.
The idea is straightforward: if you're using an off-the-shelf frontier model, it was never trained on any of your enterprise data, old or new. If you want its answers to be relevant to your business — and stay relevant — without the cost and effort of training a new base model from scratch, RAG is the way to do that.
You add a retrieval layer that pulls relevant context from your own data at query time, and the model generates answers grounded in that context rather than guessing.
This is also why RAG is already baked into many enterprise tools teams use every day: Slack AI, Atlassian Rovo, Glean, ServiceNow, Salesforce. It's become the default pattern for embedding AI into business applications at scale.
The pattern is well understood. Building it reliably is not.
RAG pipelines need a lot of moving parts: embedding models, vector databases, rerankers, LLM inference endpoints, orchestration, monitoring, access controls. The compute-intensive pieces (inference, embeddings, reranking) need GPU hardware that's expensive (and constantly evolving). The rest runs on CPU. None of it manages itself, and most teams end up bolting their RAG setups together by hand, one environment at a time.
This post walks through what a production RAG stack actually requires, where teams usually run into trouble, and where our PaletteAI platform can fit into that picture.
What you're actually building
Most of the RAG walkthroughs you'll find online focus on getting ‘something’ working — and it’s usually pretty basic. Production is a different bar.
To build a pipeline you'd actually trust with real users and real data, you need most of these pieces in place:
- An embedding model to convert documents and queries into vectors
- A vector database to store and search those embeddings (Milvus, Weaviate, Qdrant, pgvector, etc.)
- Hybrid retrieval combining semantic vector search with BM25 keyword search, because neither one alone covers every query type well
- A reranker to re-score retrieved results before they reach the model
- Query preprocessing so what the user typed actually maps to something retrieval can work with
- An LLM inference endpoint, whether self-hosted via NIM or vLLM, or an external API
- Observability so you know when retrieval quality degrades before your users start complaining
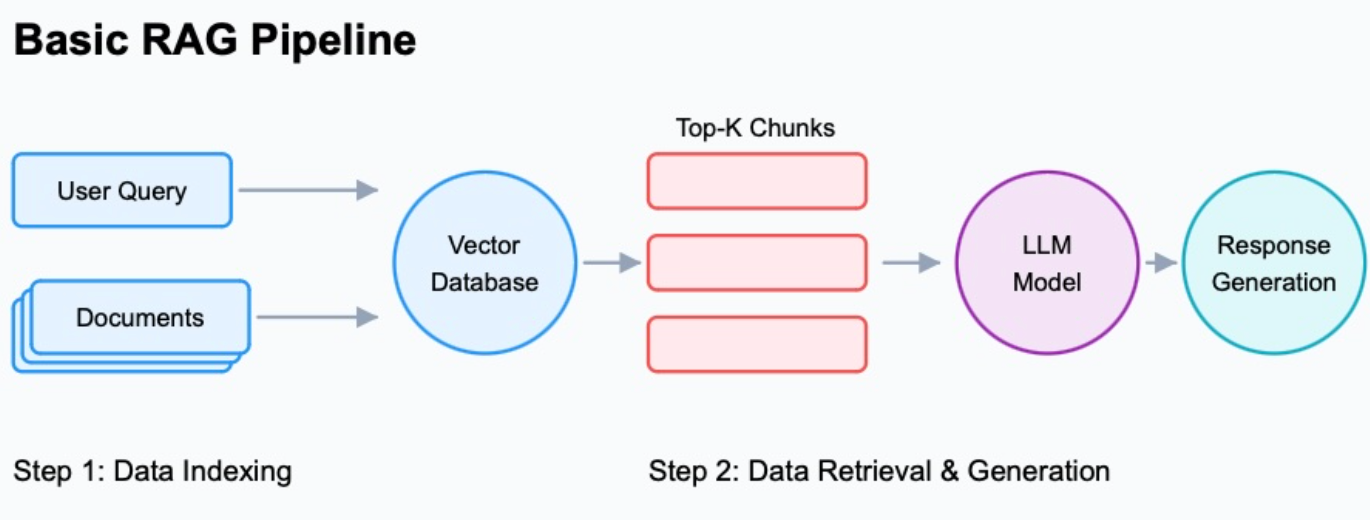
Source: Confidential Mind
To add to the complexity, each of those elements is a decision tree of its own. For example, there are half a dozen credible vector databases to pick between. If you use a reranker, it means adding cross-encoder models that are more accurate, but compute-hungry. Hybrid retrieval means running two indexes and a fusion layer on top. Query rewriting adds another model call before retrieval even starts — so if you’re to protect the user experience, that model needs to be fast every single time.
There’s a lot to think about. And none of it is optional if you want accuracy that holds up in production, because the gains from doing it right are real.
In benchmarks published by Confidential Mind, a Spectro Cloud partner, adding hybrid retrieval and a cross-encoder reranker to a basic embedding-only setup pushed answer F1 score from 0.56 to 0.63, and retrieval recall from 0.77 to 0.86.
If you’re not familiar with these metrics, they both score accuracy on a 0 to 1 scale, where higher is better. F1 is a combined measure of precision (did the model avoid returning irrelevant results) and recall (did it actually find what was relevant). So those are meaningful jumps.
It's worth being specific about what the various accuracy techniques demand from the infrastructure underneath. A couple of examples:
- Cross-encoders score query-chunk pairs directly on every request rather than relying on cached embeddings, which is why they perform better and why they're compute-intensive. Running them without blowing your latency budget requires proper GPU scheduling.
- Hybrid BM25 plus semantic search with Reciprocal Rank Fusion means two indexes running in parallel.
- Query rewriting puts a model call in the critical path before retrieval even starts.
Each of these is worth doing, and each one places real demands on whatever is running them, which is what the rest of this post is about.
Where things break down
The problems that slow RAG deployments are consistent enough that you can almost predict them going in.
Slow, manual provisioning. Standing up a new environment means installing drivers, sorting out networking, getting Kubernetes configured, and then layering in ML components one by one. Each has version dependencies. Even a test environment takes longer than it should, and they all end up slightly different from each other.
Walls between platform and ML teams. Infrastructure engineers build the environment. Data scientists need to run things on it. Without a clear interface between those two groups you get shadow environments, one-off configs, and setups nobody can reproduce when something breaks.
Environmental drift. What works in dev breaks in staging. RAG stacks have a lot of moving parts at specific versions, and without lifecycle management that drift is basically guaranteed. You usually find out when query quality gets worse and nobody can point to why.
Governance as an afterthought. Who can access which model, what data the retrieval layer is allowed to see, whether the deployment meets compliance requirements… these guardrails are rarely designed-in from the start, and retrofitting them into a running system is genuinely unpleasant.
A better way to do RAG
Now would be a good time to introduce you to a couple of very complementary solutions that tackle the ‘RAG in production’ pain.
ConfidentialMind is an AI software platform that gives IT teams a way to deliver AI as a service to their organization. Rather than each department assembling its own stack, ConfidentialMind provides ready-to-use AI endpoints: a RAG endpoint for document retrieval and augmented generation, an MCP Agent endpoint for connecting LLMs to external tools and data sources, and a model endpoint for direct LLM access through an OpenAI-compatible API. All of it runs on your own infrastructure, with enterprise-grade multitenancy, zero-trust networking, and Keycloak-based identity management built in.
ConfidentialMind sits on Kubernetes and requires a well-managed cluster with suitable GPU resources underneath it. That's where Spectro Cloud’s PaletteAI comes in.
PaletteAI provisions and manages that cluster: GPU and CPU allocation, Kubernetes lifecycle, networking, and governance enforced consistently whether you're running in a data center, a private cloud, or across multiple environments.
ConfidentialMind handles the AI workload layer. PaletteAI handles the infrastructure that layer runs on. PaletteAI can also deploy ConfidentialMind itself into a customer environment as part of a Profile Bundle, giving teams the full stack from bare metal to running AI endpoints in a single deployable blueprint.
For RAG deployments specifically, a few things stand out:
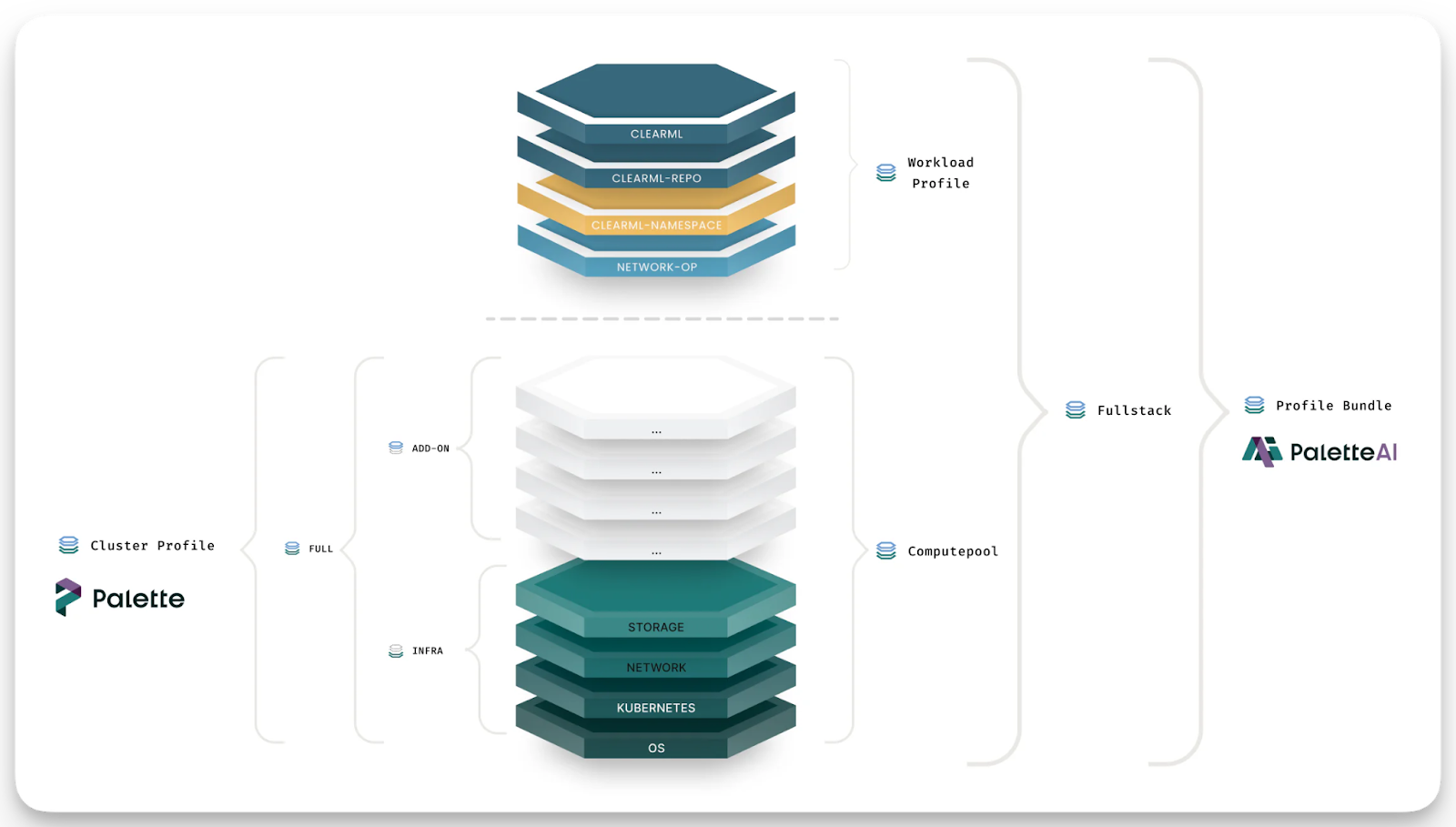
WorkloadProfiles. A WorkloadProfile is PaletteAI's declarative definition of an application-level workload: an ordered list of components (embedding service, vector DB, reranker, inference endpoint) with their configuration, dependencies, and deployment priorities. Think of it as the application counterpart to a Cluster Profile. Where Cluster Profiles define infrastructure layers (OS, Kubernetes, networking, storage), a WorkloadProfile defines the application stack that runs on top.
Profile Bundles. A Profile Bundle pairs Cluster Profiles with WorkloadProfiles into a single full-stack deployment blueprint, covering everything from the OS and Kubernetes distribution up through the running application. When a team creates a new AI deployment in PaletteAI, they reference a Profile Bundle. A RAG-specific Profile Bundle might combine a Cluster Profile (Kubernetes, GPU drivers, networking) with a WorkloadProfile that includes the embedding service, vector store, reranker, and inference endpoint, all versioned, tested, and deployable consistently across environments.
PaletteAI Studio. A library of deployable reference architectures built on NVIDIA's Enterprise AI Factory validated design, with prebuilt Profile Bundles for NIM microservices, NeMo, and Run:AI, as well as ConfidentialMind. Tested stacks on validated hardware, not assembled from community configs.
Role separation that actually works. Infrastructure teams define what's available and set the policies. ML teams and data scientists deploy within those guardrails independently, without waiting on anyone. The ops team keeps control and visibility. ML teams move at the speed they need.
What deploying ConfidentialMind on PaletteAI actually looks like
When a team deploys ConfidentialMind via PaletteAI, the starting point is a Profile Bundle: a single blueprint that combines the Cluster Profile defining the infrastructure layer with a WorkloadProfile that declares ConfidentialMind as the application stack. PaletteAI provisions the cluster, allocates GPU and CPU resources, configures networking, and brings up the Kubernetes environment. ConfidentialMind comes up on top of that, fully configured, with its AI endpoints ready to use.
From that point, ConfidentialMind takes over at the workload layer. IT administrators get a management portal where they can deploy RAG endpoints, model endpoints, and MCP agent endpoints without writing infrastructure code. Each endpoint automatically provisions what it needs: vector databases for RAG, model deployments connected to the underlying GPU resources, access controls scoped to the appropriate tenant. Business teams can stand up their own RAG systems through that portal with IT maintaining visibility and policy control throughout.
When ConfidentialMind needs to be updated, the WorkloadProfile gets updated and PaletteAI propagates it. When a new environment needs to be stood up, the same Profile Bundle is deployed again. The AI endpoint experience teams get from ConfidentialMind stays consistent because the infrastructure it runs on is consistent.
Wrapping up
RAG isn't a hard concept to understand — in fact, it’s what business users and savvy consumers expect AI tools to do out of the box. But in an enterprise build… getting it into production reliably, across multiple teams, across a mix of CPU and GPU infrastructure, with governance in place and environments that actually stay consistent. That's where the real work is.
Moving from a working proof of concept to something teams actually trust in production usually takes longer than expected, and most of that time is spent on things that have nothing to do with the model itself. Instead it’s environment consistency, GPU scheduling, access controls, update paths, making sure the team querying documents and the team managing the cluster aren't blocking each other.
PaletteAI and ConfidentialMind together are designed to shorten that gap: the infrastructure, the AI endpoints, the governance, and the multitenancy all come up together and stay consistent as you scale.
Visit spectrocloud.com to learn more about PaletteAI or book a demo with one of our experts. For a deeper look at the RAG accuracy research referenced here, the Confidential Mind write-up at confidentialmind.com/blog/building-advanced-rag-pipelines is worth the read.