

Recently we had a project that required exposing a private Kubernetes apiserver to a publicly accessible endpoint. We build the solution based on FRP (Fast Reverse Proxy). Most of the kubectl commands worked fine until we tried kubectl exec, where it stuck for a moment and then timed out. We’ve previously worked on a similar project so we know there are some tricky parts when it comes to kubectl exec because the Kubernetes apiserver needs to upgrade the HTTP/1.x connection to the SPDY protocol, in order to stream commands back and forth between kubectl and the pod/container.
What we didn’t expect was that this could be a week-long debugging experience!
So we thought we’d blog about it :)
Overall architecture
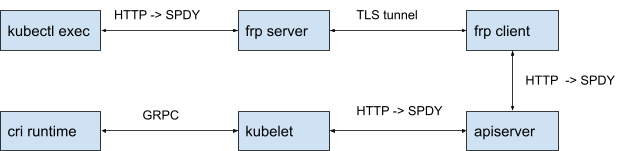
The following diagram shows the overall architecture. FRP server has a publicly accessible endpoint, and the FRP client runs within the private network. The client will initiate and set up a TLS tunnel between the server. The FRP client uses an https2https plugin to call apiserver to make sure the apiserver certificates match the domain name.
When kubectl starts exec, apiserver will try to upgrade the HTTP/1.x connection to SPDY, which is a deprecated binary streaming protocol. The upgrade will be done across all the HTTP/1.x connections.
Issue: kubectl exec/attach/port-forward doesn’t work
What we saw was, kubectl exec either stuck without printing anything, then timed out, or errored out immediately with some io error. Kubectl port-forward and attach have similar symptoms.
More verbose logging shows that, after making an HTTP POST /exec call to the apiserver, kubectl receives the HTTP response with the correct status 101 switching protocol to SPDY, together with correct response headers. However, after receiving the upgrade response, there is no more progress, no more verbose logging, then it either stuck, then timed out or immediately errored out.
Example verbose logging with port-forwarding like below:
Question 1: Where is it stuck?
The first question is, between kubectl and the FRP server, where does it actually get stuck? Is it that FRP server is waiting for kubectl, or kubectl is waiting for FRP server?
Because the stuck happens after the protocol is upgraded to SPDY, the normal HTTP verbose logs won’t help. So we built a customized kubectl binary with more debugging logs. We also enable the underlying SPDY streaming library debugging log by adding DEBUG=true to environment variables.
With this, we were able to figure out that, after kubectl receives the successful HTTP upgrade response, it tries to create a couple of streams on top of the upgraded connection. After it created the stream, it waits for a response, and that is where it stucks, it does not get the response from the FRP server. We can see the source code from here.
Question 2: Why is the FRP server not responding to kubectl?
Now we know that kubectl sends out the stream creation request, but it doesn't get a response. So the next question is, is it that the FRP server does not receive the request, or that the FRP server can not get a response from the backend so can’t respond to kubectl?
With more debugging on both FRP server and client, we put our focus on the https2https plugin within the FRP client. The plugin is nothing but yet another reverse proxy. It is used to start an HTTPS connection with valid certificates matching the Kubernetes apiserver endpoint domain name.
The plugin uses the default httputil.ReverseProxy does not have the capability to add connection-level debug logging. So we make a customized version of the ReverseProxy with more debugging logs. With this, we were able to pinpoint the error that, after the reverse proxy finishes the upgrade of the connection to SPDY when it tries to set up the pipe between the FRP server and the apiserver, it can not read from the FRP server in spc.copyToBackend(). The read action immediately returned with an error “i/o deadline reached”.
ReverseProxy source code is here.
Question 3: Can we clear the deadline on the connection?
The error message we got is ‘i/o deadline reached’, and it happens during the HTTP connection upgrade. To upgrade from HTTP/1.x to SPDY, the caller needs to hijack the underlying connection. httpserver.Hijacker() comments below:
With this specific comment ‘net.Conn may have read or write deadlines already set’, together with the error we got, we very naturally think that maybe the connection already has a deadline set somewhere before the hijack, so let’s just clear or increase the deadline.
Unfortunately, after changing all the deadline-related code in both FRP server and client, we were still not able to get past this error. So we’ll have to figure out how this deadline is set on the connection.
Question 4: Who sets the deadline?
With the goal in mind to find out where the deadline was set, we found out that the error ‘io deadline reached’ comes from the yamux package, which FRP uses as the underline streaming library. The read timeout is returned when the deadline is set on the connection. Source code can be seen here.
One thing we noticed is, the real deadline set on the stream was a very old timestamp, it’s not the normal timeout that applications usually set for read/write operations, so we think the deadline has to come from the http stack itself, not from the application (FRP).
With that in mind, we found the following code, during the hijack, in order to let the caller take full control of the connection, http.server needs to abort all the currently ongoing readings. The way to do that is to set this aLongTimeAgo as the read deadline, then wait for all current readings to timeout.
What should happen is, after the current reading operation timeout and broadcast back on the signal, this wait() will return successfully. Then it should immediately clear the readDeadline by resetting it with a zero value Time{}, so all future read operations should continue after the hijack.
But the behavior we saw is, the clear readDeadline does not have any effect, all following reads still get the “i/o deadline reached” error.
Question 5: Where is the “io deadline error” returned to?
Now we know it’s hijack sets the deadline, and the clear deadline does not take effect, we need to figure out why the reset deadline can not clear the error, and who is reading the data and triggers the error.
More debugging leads us to the http.Serve(). Before calling handler.ServerHTTP(), it starts a go routing to do background reading, which reads from the connection and triggers the error when the aLongTimeAgo deadline is set by hijack. That still makes sense.
But the confusion is, it actually ignored the error with very clear comments for the abort pending read case, so why does the error still pop up to the caller?
The fact that we only get the error after Hijack finish successfully, not within Hijack, lets us think that this error must be persisted somewhere, so even though it’s ignored during Hijack because the cr.aborted is true, but since cr.aborted is reset to false after hijack, later reads will trigger the error but won’t be ignored.
Question 6: Where is the error persisting?
With that in mind, we get down to the cr.conn.rwc.Read() code to figure out where the error is persisting. This leads us to the TLS package since all connections are TLS encrypted. When the TLS connection gets an error when reading, if it’s net.Error and the error is not Temporary, it is persisted into the TLS halfConn object, so all subsequent reads from the connection will immediately return with error. Source code is here.
Now we know that the only case this error persists is when the error is a net.Error and it is not a temporary error. We just need to get back to the original error definition to see if that’s the case.
Answer: The one-line fix
Following is the error definition in yamux:
Now everything starts to make sense. Because ErrTimeout is not temporarily set to true, TLS connection thinks this is a permanent error, and persists that error into the connection. Even though Hijack succeeds because the abort flag was set to true, all subsequent reads will return this error persisting deep into the stack!
As you can imagine, the fix is just a one-line change, set temporary to true within the error definition.
With this, kubectl exec/attach/portforward now works like a charm!
Conclusion
It was a… fun experience going through the golang net/http source code to identify and fix the puzzling issue with a simple change. The above questions look logical afterward, but because the net/http/connection stack was complicated, and the fact that there are too many moving parts/components, it was pretty easy to get lost during the debugging process not knowing which way to go. We added quite some debugging log to the kubectl/FRP/ReverseProxy, together with IDE debugger to pinpoint the issue. Hopefully, this can help you have a better understanding of how kubectl exec works, and the internals of golang net/http package. As always, if you have any questions, feel free to reach out to us — we love a good Kubernetes challenge!