




At this year’s March GTC, NVIDIA announced the open NVIDIA Agent Toolkit, and the AI-Q blueprint inside it has been on every CTO's whiteboard ever since.
It’s easy to understand the buzz around all things agentic: enterprises want autonomous agents capable of reasoning over internal data and acting against internal systems, with all of that happening inside the corporate walls. AI-Q is NVIDIA's open-source answer.
Here we'll cover AI-Q itself, why it matters specifically for private enterprise data, what's harder than it looks about running it in production, and where Palette and PaletteAI fit into the picture.
AI-Q: the open blueprint for deep research agents
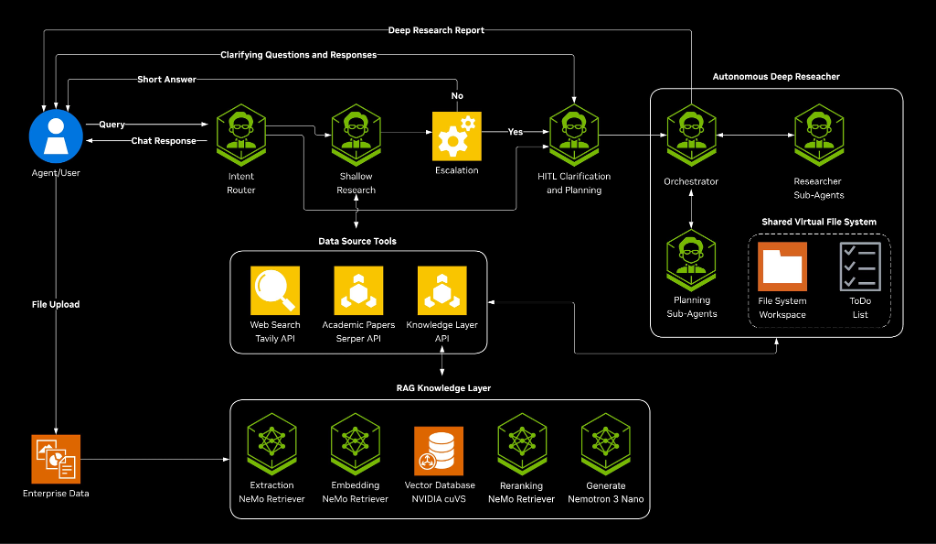
AI-Q is NVIDIA's open-source reference blueprint for building agentic search applications that connect to enterprise data and return cited, trustworthy answers using state-of-the-art models. Under the hood it's a LangChain implementation, with the NVIDIA NeMo Agent Toolkit library handling optimization and NeMo Retriever providing the fast RAG layer that grounds responses.
It’s topped both the DeepResearch Bench and DeepResearch Bench II leaderboards. The architecture is hybrid (NVIDIA Nemotron open models handle the research workload while frontier models handle orchestration), and NVIDIA reports this combination can cut query costs by more than 50% without sacrificing accuracy.
The single chatbot interface hides a small team of sub-agents underneath. An intent classifier reads each query to decide what kind of response is appropriate; a shallow researcher handles quick cited answers; for harder questions, a deep researcher pauses to do multi-step planning before generating a longer, structured report. Throughout, a knowledge layer cross-checks responses against your data to reduce hallucinations, and the built-in evaluation harnesses (FreshQA, DeepResearch Bench) let you measure quality as you tune.
In NVIDIA's own words: a developer-friendly path to building agents that "perceive, reason, and act on enterprise knowledge."
Why this matters: agents on private data
Most of the public conversation about AI agents has focused on consumer experiences, or bleeding-edge techies running OpenClaw on a Mac Mini and wondering why all their email has just been deleted.
The bigger commercial story by some margin is the enterprise agent, which depends on something both simple and difficult: getting an agent to reason usefully over private data without that data leaving the building.
NVIDIA understands this tension, which is why the GTC announcements came with an extensive partner roster. Adobe, Atlassian, Box, Cisco, CrowdStrike, IBM, Red Hat, SAP, Salesforce, ServiceNow and 17 others have signed on, and their customers are all asking variations of the same question: how do we point this at our own data, without that data leaving our control?
For sectors like financial services, defense, healthcare and government, the easy hyperscaler answer just doesn't fly. AI-Q on the other hand is open, deployable on-premises, and designed so enterprise data stays where it belongs. The NVIDIA AI Data Platform reference design, into which AI-Q plugs directly, takes the same posture of bringing the agent to the data, not the other way around. Production-grade RAG itself is a non-trivial infrastructure problem we've covered before, and AI-Q standardizes a strong answer on top of NeMo Retriever with the agent intelligence built in.
Spectro Cloud is also a silver founding member of the Agentic AI Foundation (AAIF), the Linux Foundation body set up in December 2025 to steward agentic standards including the Model Context Protocol. We sit alongside Amazon, Anthropic, Google, Microsoft and OpenAI in that work, on the view that a technology this consequential (and with this much risk) shouldn't be defined inside any single vendor's stack. AI-Q's open licensing aligns with that view, and so does what we're doing to make it production-ready at scale.
Past the Helm chart
If you read NVIDIA's getting-started docs[A2] you'd be forgiven for thinking AI-Q is a weekend project, even accounting for the basic fact that it assumes a K8s cluster already exists. Pull the Helm chart, set a few environment variables, point it at an NVIDIA NIM endpoint, and you've got a top-ranked deep research agent answering questions. Lovely.
Then you read the production considerations page, and the picture gets considerably busier.
A managed PostgreSQL instance becomes a requirement, holding three separate databases for jobs, checkpoints and summaries, and the initialization scripts that ship with the project don't auto-run against managed services, so they need to be applied manually. The stateless backend can be horizontally scaled behind a load balancer, but you'll want an external Dask scheduler if you need shared task execution across instances. Each underlying model needs a NIM endpoint, and each retrieval flow needs the appropriate NeMo Retriever , with their own resource profile. NVIDIA's own warning in the AI-Q repo is pleasingly direct on the security front: "Missing AuthN & AuthZ will result in ungated access to customer models." That's the company's polite way of saying you should probably take a look at that.
The wider stack that AI-Q itself doesn't promise to handle is at least as much work again. The host needs its NVIDIA GPU drivers and the GPU Operator kept current, with MIG, NVIDIA vGPU™ or time-slicing layered on if you want to share GPUs across workloads. Operating systems need lifecycle management. Container images need scanning and patching. Multi-tenant network isolation has to keep the finance team's agent away from the legal team's documents, with RBAC, quota management and tenant-scoped GPU pools tying access to identity. Clusters need to autoscale; sovereign deployments need air-gapped image and Helm chart distribution; and everything in the stack needs patching as NVIDIA, Kubernetes and the model ecosystem ship their next round of updates, which they do often. At time of writing, the last Github release for AI-Q was just 16 hours ago.
Few enterprises end up running enterprisewide agent infrastructure on a single cluster. The realistic number depends on your org chart, but it’s likely in the tens or more, spread across regions, business units, sovereign environments and edge sites, with each cluster needing the same scaffolding.
You might imagine that many agentic projects stall out somewhere around this point, or turn into a pile of bespoke YAML maintained by one engineer who really needs a vacation. Building a platform that other teams in the business can rely on… well, it’s certainly more than a weekend project.
Where Palette and PaletteAI come in
This is where we come in, and please forgive the sales pitch. Our Palette and PaletteAI platforms are designed for just this kind of enterprise infrastructure stack lifecycle management. Together they cover the full ML infrastructure stack, from bare metal provisioning to AI workload management, in a single declarative platform. Concretely for AI-Q:
Reusable cluster profiles. AI-Q runs on a validated profile that bundles together the OS, Kubernetes, GPU operator, NeMo Retriever, NIM endpoints, the AI-Q Helm chart and the configuration glue between them. You can reuse this profile to deploy consistently across data centers, edge sites and cloud, so every additional cluster gets the same stack the same way.
Lifecycle management beyond Day 0. Drivers, firmware, Kubernetes versions, GPU operator releases and the AI-Q stack itself all have to keep pace with a fast-moving ecosystem, and Palette is built around automating exactly that. Policy-driven upgrades, with rollback, are standard. The practical effect is that AI-Q version bumps become routine operational work (again, consistent across multiple clusters).
Efficient GPU sharing. Native GPU Operator integration with MIG, vGPU and time-slicing means the GPUs running AI-Q's NIM and Retriever pipelines can be shared across workloads. As we've covered before, enterprise GPU utilization commonly sits around the 13% mark, so there's real money to be saved by putting MIG to work alongside agentic workloads.
Multi-tenancy at the right layers. Tenant- and project-scoped access, GPU quotas, namespace isolation and resource-scoped deployments handle the Kubernetes layer of multi-tenancy. For multi-tenant AI at scale that's part of the picture; physical and fabric-level isolation matter just as much, which is where our Aviz Networks integration comes in. Between them, an enterprise has the controls it needs before letting two teams share a cluster.
Security and compliance built in. Our PaletteAI VerteX edition adds FIPS 140-3 validated cryptography, support for air-gapped operation, DPU-backed zero-trust networking, and the compliance credentials regulated industries need (ISO 27001, SOC 2 Type II, FedRAMP Low and Moderate in process). It's also the path for sovereign AI deployments where AI-Q has to run inside national borders.
Self-service with guardrails. Through our UI or APIs, platform admins define the templates and policies, while AI practitioners (and increasingly the agents themselves) consume those templates through self-service interfaces. It's the same separation of concerns platform engineering brought to applications, now applied to agents.
Taken together, that's an AI-Q deployment your AI teams can use without your platform team having to hand-hold it every week.
Talk to us
Building enterprise AI agents looks straightforward in the demo and harder once it has to scale. If that's where your team is right now, get in touch. Palette and PaletteAI take responsibility for the production scaffolding the AI-Q docs don't promise to handle (multi-tenancy, GPU sharing, lifecycle management, air-gapping and the rest), leaving your AI team free to focus on the agent itself.
Book a PaletteAI demo and we'll walk through what an AI-Q deployment would look like in your environment.