










If you're running an MSP or a sovereign cloud and you've got customers asking for GPU access to run LLMs, you've probably already felt this pain.
A user requests a GPU to run a 7B parameter model that requires maybe 14GB of VRAM, and you hand them an entire 96GB card. That's 82GB (and several thousand dollars of capex) sitting there doing absolutely nothing apart from consuming power, while the next customer waits in line.
Multiply that across dozens of tenants and you start to see why GPU utilization in Kubernetes clusters sits at a depressing 15-25% on average. A recent analysis by Wesco of over four thousand Kubernetes clusters found that average GPU utilization was only 13%, with memory usage rarely exceeding 20%. OpenAI themselves estimate around 33% GPU utilization across their infrastructure, and they're one of the most sophisticated operators on the planet.
The GPU-as-a-Service market is projected to hit $26 billion by 2030, and sovereign cloud demand is a huge driver of that growth. Countries are pouring money into domestic AI infrastructure. For example, Kuwait launched its first sovereign AI-enabled data center with NVIDIA late 2025, Deutsche Telekom is standing up 10,000 Blackwell GPUs in Munich, and India's national mission is partnering with NVIDIA to install thousands of GPUs for sovereign cloud builds.
The demand is clearly there. But the economics only work if you can actually utilize the hardware you're paying for.
So let's talk about what's available today to solve this, how it works, and what a practical self-service architecture looks like for MSPs and sovereign cloud operators.
GPU partitioning with Multi-Instance GPU (MIG)
NVIDIA's Multi-Instance GPU (MIG) technology is the foundation.
Unlike time-slicing, which rapidly switches between workloads on the same hardware (with no memory isolation), MIG physically partitions the GPU at the silicon level. Each partition gets its own dedicated streaming multiprocessors, its own memory, and its own L2 cache.
Workloads in one partition literally cannot see or interfere with workloads in another. This is the kind of isolation you need when you're offering GPUs to paying tenants who expect predictable performance, and privacy for sensitive data and workloads.
Not every GPU supports MIG and, what’s more, the support varies across the different GPU families. The RTX PRO 6000 Blackwell (96GB) supports up to 4 instances, the H100 and A100 go up to 7, and the RTX PRO 5000 tops out at 2. Consumer GPUs and lower-tier professional cards like the RTX PRO 4500 Workstation Edition? No MIG at all, you're stuck with some level of soft software isolation with time-based sharing (time-slicing) or Multi-Process Service (MPS).
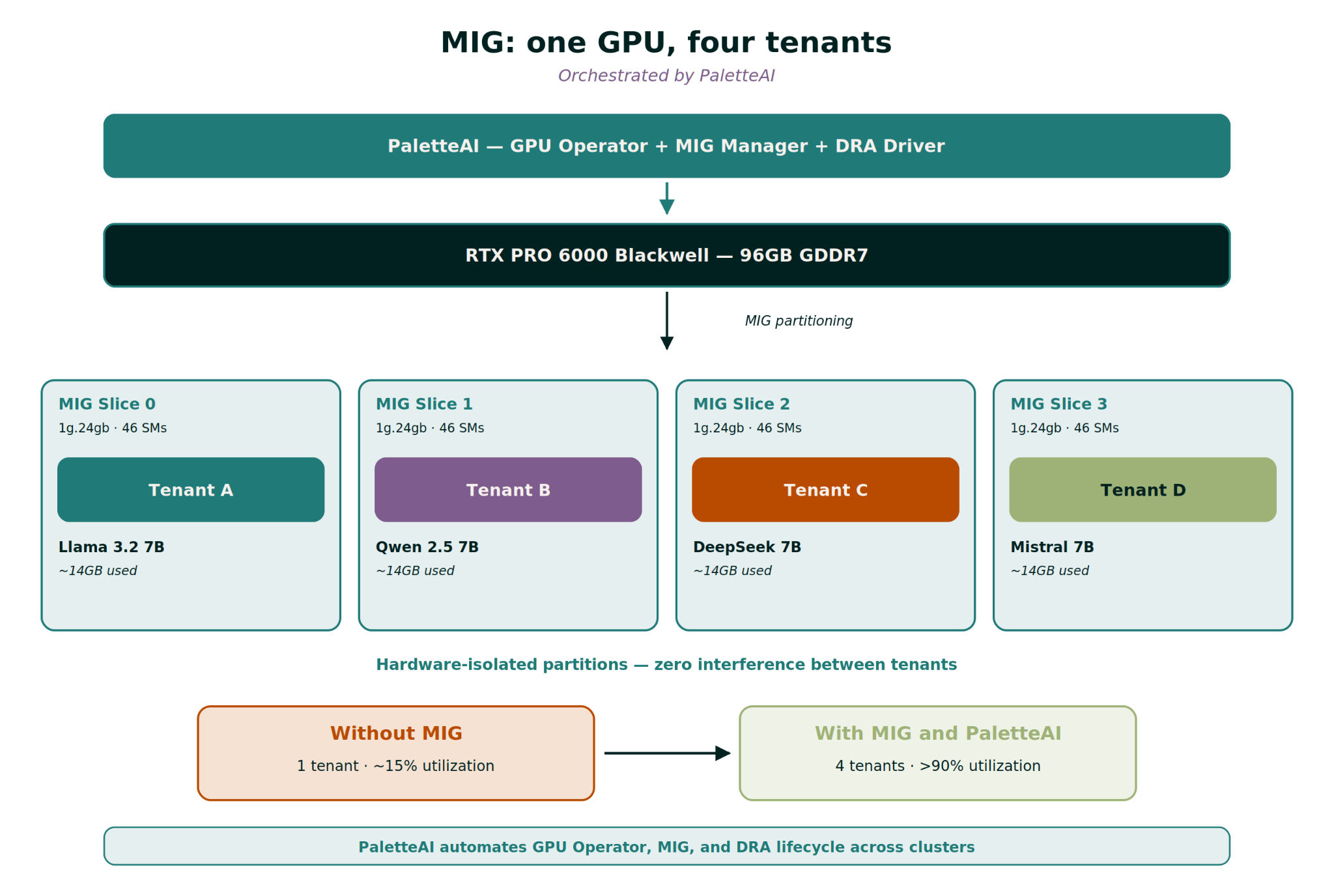
For the RTX PRO 6000 Blackwell Server Edition specifically, the math works out nicely for serving multiple LLM inference workloads simultaneously. You can slice it into four 24GB partitions (profile 1g.24gb), and a 7B parameter model in FP16 needs roughly 14GB. That means that you can comfortably run four isolated 7B LLMs on a single GPU. Four tenants, one card, with hard and strict hardware-level isolation. The utilization story completely changes.
On top of all of this, if we look at how model quantization is evolving and the fact that we can now run FP4 on newer models, this means that we can fit even larger LLMs onto the same amount of memory, without meaningful degradation in performance.
Why partitioning matters for MSPs and sovereign clouds
MIG is cool from a technical standpoint, but the business case is more important. A GPU like an NVIDIA RTX PRO 6000 Blackwell is not cheap. If you're assigning the whole thing to one customer running a 7B model, you're monetizing maybe 15% of its capacity. With MIG, you can conceivably serve four customers from the same card.
Even accounting for contingencies, overprovisioning and bin-packing inefficiencies, there’s obvious attraction in the idea of getting 4x the revenue from the same capex investment. And the flipside is that by better utilizing the GPUs you already have on hand, you can defer or shrink imminent future GPU purchases and facility buildouts and ease some of the stress of market GPU shortages. For the average MSP, wasting 60-70% of their GPU budget on idle resources, improving utilization conservatively from 30% to 80% can effectively double infrastructure capacity without buying any new hardware.
This particularly matters for sovereign cloud operators constrained in their ability to source temporary capacity elsewhere. With data residency concerns, you can't just burst to your usual hyperscaler when your local GPUs appear "full". Evolving sovereignty regulations and geopolitical tensions are expected to keep driving demand for domestic AI infrastructure, which means that you must maximize what you've got within your borders. MIG lets you do exactly that.
From GPU Operator to self-service with DRA
The implementation has three layers, and they build on each other. Let's walk through each one, assuming that we are using an RTX6000 PRO Blackwell Server Edition.
Layer 1: The GPU Operator
NVIDIA's GPU Operator handles all the unglamorous but critical stuff: driver installation, container toolkit, device plugin, monitoring. For MIG, it also deploys a MIG Manager that watches for node labels and automatically partitions GPUs. You can install it via Helm with the MIG strategy specified upfront:
helm install gpu-operator nvidia/gpu-operator \
--set mig.strategy=single \
-n gpu-operator --create-namespace
Then you label a node and the MIG Manager handles the rest:
kubectl label node gpu-node-01 nvidia.com/mig.config=all-1g.24gb --overwrite
Within a minute or two, that single 96GB GPU becomes four 24GB isolated instances. The device plugin picks them up and advertises them to Kubernetes. With the "single" strategy, they show up as nvidia.com/gpu resources, just like they would natively without MIG setup. So existing pod specs don't need to change at all: backwards compatible, zero application changes.
If you need different partition sizes on the same GPU (say two small slices and one large one), you switch to "mixed" strategy and create a custom ConfigMap with the exact layout that you need. This is more flexible but requires pods to request specific resource types like nvidia.com/mig-1g.24gb. For brownfield deployments this might be considerably disruptive given that running GPUs will have to evict all their workloads in order to change the MIG configuration, as well as the pod specs for those workloads will have to change.
Layer 2: Dynamic Resource Allocation (DRA)
This is where things get interesting for self-service. Dynamic Resource Allocation (DRA) reached General Availability in Kubernetes 1.34. It’s already used at scale by organizations like CERN and it fundamentally changes how GPUs are scheduled. Instead of the old model where pods request a count of GPUs (nvidia.com/gpu: 1), DRA introduces a claim-based system. Pods describe what they need through ResourceClaims, and the system figures out which device to assign.
A good way to understand it better (at least what worked for me) is to think of it like storage in Kubernetes. You don't typically hardcode a specific disk into your pod spec. You create a PersistentVolumeClaim, reference a StorageClass, and let Kubernetes handle the provisioning. DRA does the same thing for GPUs. DeviceClasses are your StorageClasses, ResourceClaims are your PVCs.
The NVIDIA DRA driver publishes ResourceSlices on each node, advertising available devices with all their attributes: memory size, architecture, MIG profile, compute capability. The scheduler matches claims against these attributes using CEL expressions.
To set it up, you install the GPU Operator with the legacy device plugin disabled (since DRA replaces it), then install the NVIDIA DRA driver separately. The important thing is that MIG partitioning is still handled by the GPU Operator as DRA doesn't create MIG slices dynamically, it "only" handles the smart allocation of slices that already exist.
Layer 3: Self-service abstraction
And here's the part that matters most for MSPs. You create custom DeviceClasses that map to tenant-friendly "t-shirt sizes". The platform team defines these once and on the other side, the users never see MIG profiles, CEL expressions, or node labels.
For example, you might define three tiers:
- gpu-small: Matches MIG slices with at least 20GB memory. Perfect for 7B models.
- gpu-medium: Matches slices with at least 40GB. Handles 13B models comfortably.
- gpu-large: Matches full GPUs with 80GB+. For 34B models or fine-tuning workloads.
Each DeviceClass is just a few lines of YAML with a CEL expression filtering on memory capacity. The tenant's deployment then looks like this:
### Platform team creates the abstraction once
apiVersion: resource.k8s.io/v1
kind: DeviceClass
metadata:
name: gpu-small
spec:
selectors:
- cel:
expression: >-
device.driver == 'gpu.nvidia.com' &&
device.attributes['gpu.nvidia.com'].profile == '1g.24gb'
---
### User app references gpu-small, no MIG knowledge needed
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: my-model-gpu
spec:
spec:
devices:
requests:
- name: gpu
exactly:
deviceClassName: gpu-small
---
apiVersion: v1
kind: Pod
metadata:
name: llama-7b
spec:
resourceClaims:
- name: gpu
resourceClaimTemplateName: my-model-gpu
That's it. The user picks a size, deploys their NIM container, vLLM server or any other GPU accelerated workload and Kubernetes with DRA handles everything else. No GPU expertise required, no infrastructure tickets. Self-service, isolated and metered.
Putting it all together
On a single NVIDIA RTX PRO 6000 Blackwell-equipped node running Kubernetes 1.34, here's what the stack looks like end to end:
- GPU Operator installs drivers and MIG Manager
- Node is labeled with nvidia.com/mig.config=all-1g.24gb (4 slices)
- NVIDIA DRA driver discovers the MIG devices and publishes ResourceSlices
- Platform admin creates DeviceClasses: gpu-small, gpu-medium, gpu-large
- User A deploys Llama 3.2 7B — requests and gets scheduled on one 24GB MIG slice via gpu-small
- User B deploys Qwen 2.5 7B — gets another 24GB slice
- User C deploys DeepSeek R1 7B — third slice
- User D deploys Mistral 7B — fourth slice
Four customers (or internal teams) with four different LLMs sharing one GPU. There’s zero interference between tenants, both in terms of resource contention and security. Each tenant thinks they have their own GPU. Each user's performance is guaranteed by hardware isolation, not software scheduling tricks.
For sovereign cloud operators, this is particularly compelling. You're maximizing the value of every GPU within your national borders. For MSPs, you're turning one GPU into four easily billable units: each MIG GPU slice shows up as a separate named resource, so it will appear in logging, observability etc for MSP customer support, for showback and chargeback, etc. And for both sovereign clouds and MSPs, the self-service layer means your platform team isn't manually provisioning GPUs for every new model deployment.
The GPU-as-a-Service market isn't slowing down. AI server shipments are forecast to grow over 20% in 2026 alone, driven by CSP and sovereign cloud demand. The operators who win won't be the ones with the most GPUs, they'll be the ones who use their GPUs the best. MIG plus DRA are crucial to get right for you to get there.
The scale and day-2 challenge
The stack we described above, of GPU Operator, DRA and MIG, needs to be installed and configured on each host, along with associated components like observability tools. Each component in the stack, including Kubernetes, needs upgrading on a schedule at least three times per year.
It’s vital — and your customers expect it — to ensure that your infrastructure is not only up to date, but consistent, free of configuration drift, and patched to close known vulnerabilities on an ongoing basis. If you’re not on top of this, everyday tasks like troubleshooting customer tickets becomes that bit more challenging. If operational tasks are manual, you’re not only burning costly team hours and eating into your margins, but risking customer experience by exceeding maintenance windows and other SLAs.
If you want to avoid many of the manual steps of installing and taking care of both MIG and DRA setups. This is where Spectro Cloud comes in.
Automating the MIG stack at scale
Our Palette and PaletteAI infrastructure management platforms have native support for the NVIDIA GPU Operator with MIG, as well as DRA, all out of the box. They’re both designed to operate at AI factory scale, so no matter how many nodes and clusters you’re building, they give you a single platform to deploy and manage your environments.
Palette has always been a tool for platform teams to manage infrastructure; PaletteAI goes a step further, abstracting away the complexity for both AI platform teams and AI practitioners.
Let’s see how it unfolds.
In this scenario, the platform team selects the MIG profiles and sizes that they need for each compute pool that they are deploying, via drop-downs from the PaletteAI interface.
PaletteAI automatically detects which GPUs are part of each compute pool and it intelligently only shows the platform team the MIG profiles available to match those.
For each project in PaletteAI, the platform team can create ‘t-shirt size’ configurations that match their specific needs, as well as create limits for GPU utilization on a per-request or per-project basis.
So, when the AI practitioner goes to deploy their workload, they only need to select the t-shirt size that is available to their allocated project.
All of this is tied together with fine-grained RBAC.
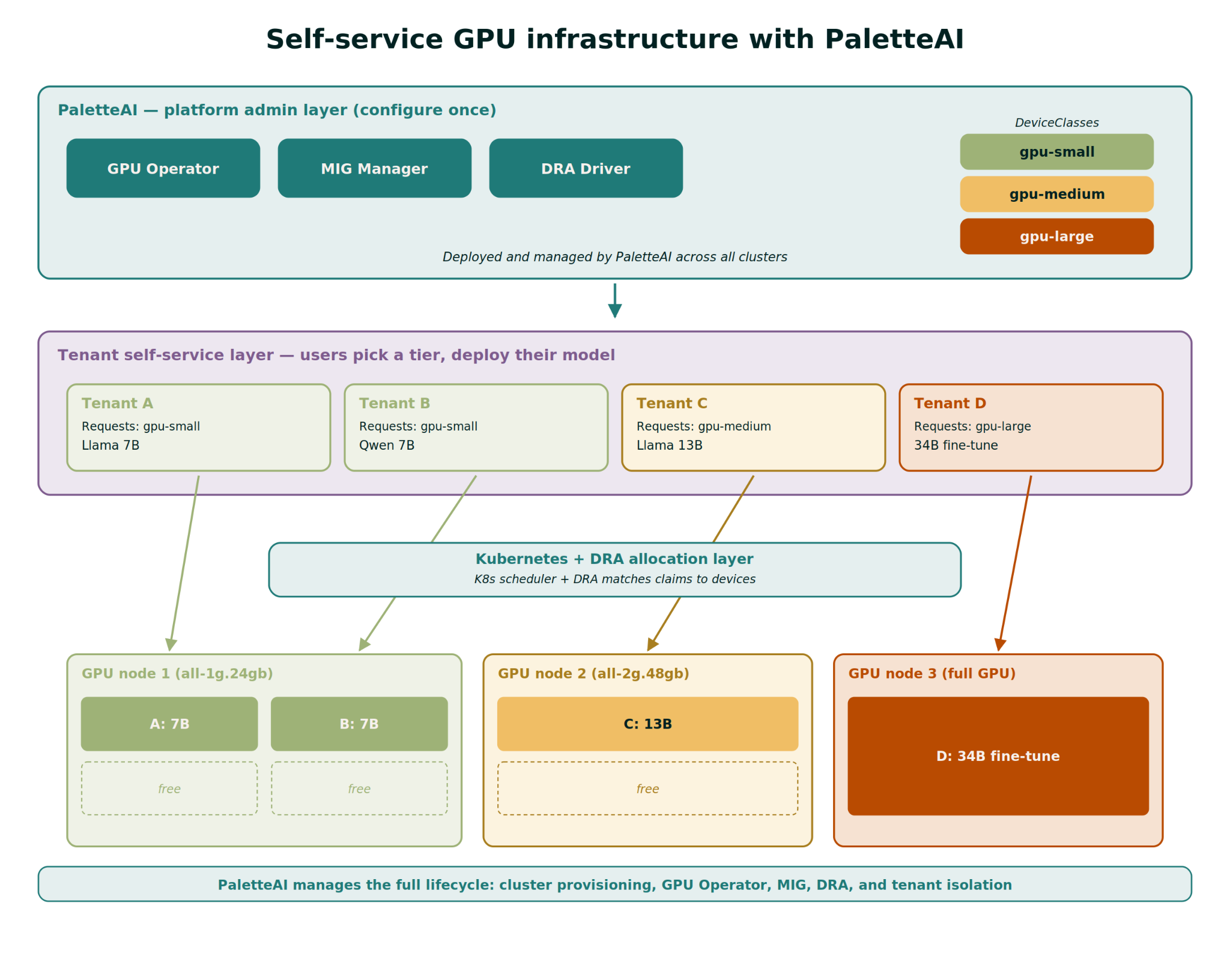
And at day 2 and beyond, PaletteAI helps platform teams keep the whole AI factory humming, simplifying scaleout of newly provisioned hardware, plus updates and configuration changes to the entire stack from OS to K8s to model.
The end result is that tenants get the right GPU slices to run their preferred workloads, self-service. Combining MIG and DRA drives utilization of shared GPUs up to as much as 90%, with safe hardware isolation between partitions. And platform teams save time and avoid disruption through a single platform that automates the entire infrastructure lifecycle — translating into better customer experience and greater profitability.
If you’re a neocloud, sovereign AI provider or MSP — we bet you need this in your environment. The best way to get started is to book a meeting with one of our AI experts to show you how it all works in action. What are you waiting for?