














At our KubeCon Europe after-party in Amsterdam this past March, someone walked up to the Sedai and Spectro Cloud crew — talking side by side — and asked the question we've been hearing for months: "Wait, don't you two kind of do the same thing?"

We looked at each other and laughed. If you squint at a product page, sure, you could talk yourself into seeing overlap. Both companies work with Kubernetes. Both care about cost efficiency. Both say "optimization" a lot.
The truth is we solve different problems, at different layers of the stack. And the disconnect between those layers is where many enterprises (possibly yours too) are hemorrhaging money.
Spectro and Sedai have been collaborating for several months now — on projects with joint customers, on our technical integration… and yes, on the occasional bar tab in Amsterdam. The more we work together, the more obvious it becomes that these two products belong side by side.
So, we figured it’s time to write it down.
The Day 2 problem nobody's solving well
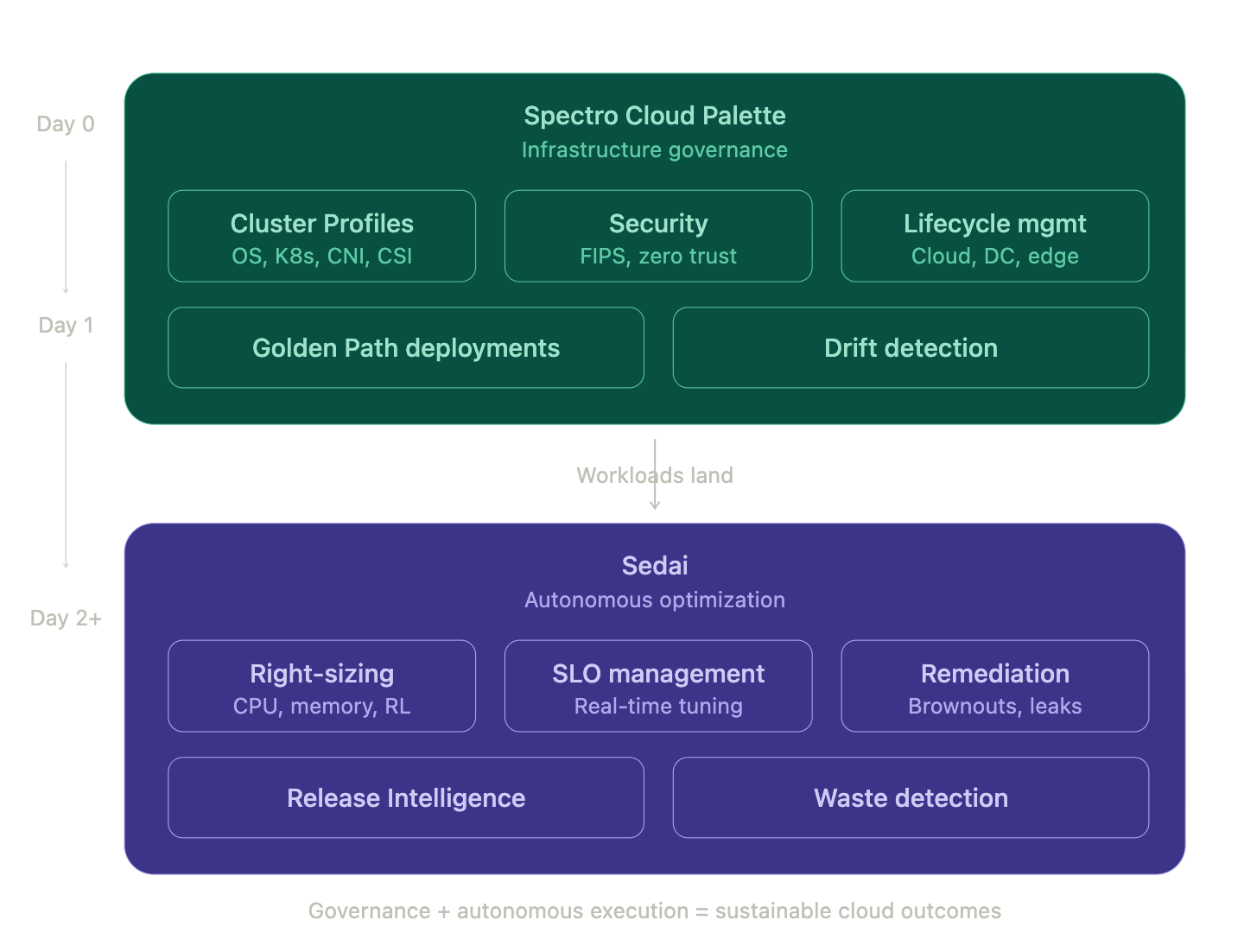
A common scenario: your platform team spends months getting their Kubernetes house in order. They standardize clusters, lock down security policies, automate provisioning, build a golden path for developers. Day 0 and Day 1 are taken care of and the infrastructure is consistent, compliant, repeatable. Phew.
But within a few months of workloads running, your cloud bills are climbing. Why?
In a tale as old as time, developers have padded their resource requests with generous safety margins (“just give me 4Gi of memory, I don't want to get paged at 2am”). Autoscalers don’t help: they were tuned to defaults that made sense during initial deployment but haven't been revisited since. Same for memory limits, set based on load testing that doesn't reflect actual production traffic.
Nobody's doing anything wrong in this story, exactly (we love a blameless retro, right?). It’s just that workloads and their underlying infrastructure need continuous, real-time tuning, and no human team can keep up with that across hundreds of services and dozens of clusters. The governance is solid. What's missing is the optimization.
Most enterprises try to close this gap with visibility tools: o11y dashboards, recommendation engines, FinOps reports. These are useful, sure! But they create a backlog, not a solution. Someone still has to read the recommendation, validate it, write the PR, get it reviewed, and apply it. Multiply that by every service in every cluster, and you've described a full-time job nobody was hired to do… not SREs, not devops, and certainly not the app developer who owns the workload.
The result is that cloud costs keep rising, putting platform teams in reactive mode. All that governance work from Day 0 and Day 1 is eroded because nothing is actively protecting it on Day 2.
Two layers, one stack
The more we've worked together, the clearer this painful picture has become… and the clearer the needed solution too.
Spectro Cloud and Sedai sit at two distinct layers of the Kubernetes stack, and both layers need to work well for enterprises to get the outcomes they're paying for.
Spectro Cloud Palette owns the infrastructure lifecycle. Our Cluster Profiles give platform teams a declarative blueprint for everything from the OS and Kubernetes distribution to the CNI, CSI, and add-on layers. Palette deploys and manages that full stack across cloud, data center, and edge, with powerful drift remediation, built-in security and FIPS compliance if you need it. You can think of it as the governance foundation.
Sedai owns configuration optimization after the workloads get deployed at Day 2 and beyond. Using reinforcement learning, Sedai continuously analyzes how each service actually behaves in production (CPU usage patterns, memory consumption, response latency, traffic patterns and dependencies) and autonomously right-sizes resources in real time. Not recommendations you'll maybe get around to next sprint — actual changes, executed safely, with automatic rollback if something moves outside acceptable bounds.
One builds and maintains the road. The other keeps every vehicle on it running at peak efficiency. You need both, and critically, each one makes the other better.
Why governance enables autonomy (not the other way around)
Autonomous optimization sounds great in a pitch deck, but it makes platform teams nervous for good reason. If your clusters aren't consistently configured, automated changes can have unpredictable side effects. Mixed Kubernetes distributions, different OS versions, inconsistent security policies: all of that creates a moving target for any optimization engine trying to learn your workload patterns.
That's where Palette's governance becomes Sedai's secret weapon. When every cluster is deployed from the same standardized Cluster Profile, Sedai operates on a stable, predictable surface. It learns faster, acts more confidently, and delivers more consistent results across environments. Guardrails don't constrain autonomy; they make it safe.
From the Sedai side, this is a meaningful difference. Customers running Sedai on well-governed clusters see stronger optimization results and fewer edge cases than those running across a patchwork of hand-rolled configurations. The more uniform the canvas, the more precisely Sedai can tune what's running on it.
From the Spectro Cloud side, Sedai solves the question Palette customers inevitably ask three to six months after go-live: "Our infrastructure is standardized and secure, but our cloud bill is still climbing. Now what?" That "now what" is exactly where Sedai picks up.
How the integration works today
The Sedai Smart Agent is available as a pack in the Palette Community Registry. Add it to a Cluster Profile, deploy, and Sedai connects to your cluster through standard Kubernetes APIs. No custom plumbing, no separate installation: the same pack-based model Palette customers already use for everything else in their stack.
Once installed, Sedai typically needs two to four weeks to learn your workload patterns before optimizations reach full effectiveness. During that ramp-up, you choose your comfort level across three modes: Datapilot (recommendations only), Copilot (review and approve each change), and Autopilot (full autonomy). Most customers start in Copilot, build trust watching Sedai make the right calls, then graduate to Autopilot. Trust is earned, not assumed.
For Helm-based add-on layers in Palette, the integration works cleanly today. Palette installs the pack, Sedai handles workload-level optimization, and the two systems stay out of each other's way. We're also working on deeper integration patterns for tighter coordination between Palette's desired-state model and Sedai's runtime optimizations. More on that soon.
What this looks like for real teams
A few scenarios where the combination clicks.
The FinOps team drowning in recommendations. You've got Kubecost or your cloud provider's cost explorer showing waste everywhere, but nobody has bandwidth to action the findings. Palette governs the environment; Sedai eliminates the waste autonomously, continuously. Customers typically see a 30–40% reduction in over-provisioned resources without anyone touching a YAML file.
The enterprise that nailed the migration but lost the plot on Day 2. The Kubernetes transformation went well six months ago. But efficiency has eroded since. Resource requests are stale, HPAs haven't been revisited, and nobody's actively optimizing because everyone moved on to the next project. Palette keeps the infrastructure governed; Sedai keeps it efficient — continuously, not just at migration time.
The team that can't hire fast enough. Every new cluster or cloud region creates a linear need for more SREs to watch dashboards and tune configurations. Palette extends the Golden Path to new environments without proportional headcount growth. Sedai manages resource efficiency at every node. Together, they let you scale infrastructure without scaling your ops team at the same rate.
Answering the overlap question, for good
We get why people ask. The cloud native ecosystem is crowded, product positioning blurs together, and when two companies are standing next to each other at a party, it's natural to wonder.
The short answer: Spectro Cloud doesn't optimize your workloads, and Sedai doesn't provision or govern your infrastructure. Different problems, different technology, better together.
What's next?
We're deepening our mutual technical integration, and building out the playbook for customers who want to move from well-governed infrastructure to self-optimizing infrastructure. The Sedai Smart Agent pack in Palette is just the starting point.
If you're running Palette today and wondering what happens after Day 1, we should talk. If you're using Sedai and want a more consistent foundation to optimize against, same. And if you're stuck in the cycle of over-provisioning, manual tuning, and cloud bills that never seem to go down... that's exactly the problem we built this partnership to solve.
Reach out to your Spectro Cloud or Sedai account team, or get in touch with either of us directly, or your preferred system integrator partner. We're always up for a conversation about what the full cloud lifecycle looks like when governance and optimization work as one.