




The telecom industry has been building toward this moment for decades. Layer by layer, generation by generation, operators have assembled some of the most complex infrastructure on the planet — distributed data centers, fiber rings, radio towers, edge nodes. That investment, long treated purely as connectivity plumbing, is now becoming something far more valuable: the physical foundation for a new kind of AI economy.
AI is no longer a workload that lives in a handful of hyperscale data centers. As inference demands grow and latency requirements tighten, intelligence has to move closer to where data is generated and where decisions need to be made. Telcos, with their distributed footprint, trusted national relationships, and carrier-grade operating discipline, are the natural owners of that distributed compute layer. The question is no longer whether to build it — it's how.
That's the problem NVIDIA's AI Grid reference design is proposed to solve, and it's the architecture at the center of this post. Here we'll look at what AI Grid actually means, why it matters for telcos right now, and how SpectroCloud's PaletteAI platform helps operators put it into production.
From AI factory to AI grid: what changed
Until recently, the dominant model for enterprise AI was centralized: build one large AI factory, concentrate compute there, and serve everything from it. That model works well for training and batch inference. It breaks down when workloads are latency-sensitive, when data can't leave a jurisdiction, or when edge applications — like RAN optimization, network digital twins, or real-time anomaly detection — need to run close to the network.
NVIDIA's answer, introduced as a central theme at GTC 2026, is to evolve beyond the isolated AI factory toward a connected, distributed AI Grid. As NVIDIA describes it in the GTC session 'AI Grid Explained: From Secure AI Factories to Distributed Intelligence,' isolated AI factories must scale into a grid that can run diverse workloads — from edge AI applications and telco network functions to internal AI services, digital twins, and RAN — while delivering the right performance and efficiency across data centers and sites of all sizes.
The AI Grid isn't a single product. It's a reference design for how those nodes connect, how workloads are routed between them intelligently, how security is enforced across the fabric, and how the whole thing can be monetized as a service. For telcos, it's the blueprint for turning distributed infrastructure into a revenue-generating AI platform.
What the AI Grid architecture looks like
The AI Grid stack is cleanest understood as four layers, each building on the one below.
At the bottom sits infrastructure as a service — the hardware substrate that makes multi-tenancy, hard isolation, and global load balancing possible. NVIDIA Spectrum-X Ethernet handles networking here, alongside NVIDIA and partner solutions for compute, storage, database management, and both AI and RAN orchestration. Using NVIDIA DSX Air, the infrastructure is developed and verified without the need to install hardware, resulting in faster time to market for a verified, error-free AI factory.
The next layer up is container as a service, which brings in Kubernetes, supporting containers, and Run.ai for intelligent GPU scheduling. This is where the platform starts to abstract away from bare metal and gives AI teams a consistent surface to work on regardless of which physical site they're running on.
Platform as a service sits above that, and it's where NVIDIA AI Enterprise (NVAIE) anchors the stack. This layer for example can include NVIDIA Dynamo for distributed inference, NVIDIA NIMs for large language models, and NVIDIA Aerial for optimized RAN workloads. Multi-cluster cloud management at this level is what makes the grid feel like a single platform rather than a collection of disconnected sites.
At the top, AI as a service provides the user-facing control plane — a single pane of glass for customer onboarding, tokenization, monetization, and semantic routing. This is also where the AI Grid Orchestrator lives, which coordinates where workloads run across the federated infrastructure.
Hardware choices vary by workload tier. Training and fine-tuning points toward NVIDIA HGX B300 for raw throughput. For the distributed inference and telco compute nodes that make up the bulk of an AI Grid deployment, NVIDIA recommends the RTX PRO 6000 in 2U or 4U configurations — up to eight GPUs per node — which hits the right balance of compute density, power envelope, and cost for edge data center environments.
What telcos need to make this work in production
Understanding the reference design is the easy part. Deploying and operating it across dozens of distributed sites — while meeting carrier-grade reliability standards, regulatory constraints, and multi-tenant security requirements — is where most teams run into friction. A few considerations are worth flagging specifically:
- Security by design. Zero-trust architectures, continuous threat detection, encrypted traffic flows, and AI-driven anomaly detection to protect both infrastructure and subscriber data — these can't be bolt-ons. They need to be built into the platform from the start.
- Network isolation and segmentation. Strong workload isolation, slice separation in 5G, and multi-tenant controls prevent lateral movement and protect service integrity across tenants.
- Automation and orchestration. Policy-driven automation reduces manual operations, enables faster service rollout, and prevents the configuration drift that causes incidents at scale.
- Scalability and cloud-native readiness. Kubernetes-based architectures with elastic infrastructure that can dynamically scale with traffic demands — not just at a single site, but across the grid.
- Resilience and high availability. Built-in redundancy, self-healing capabilities, and disaster recovery strategies to maintain carrier-grade uptime across every node in the fabric.
These aren't new requirements for telcos — they've been managing infrastructure at this level for years. What's new is the need to extend that discipline across an AI software stack that moves faster, is managed by more teams, and spans a much wider surface area than traditional network functions.
Spectro Cloud PaletteAI: orchestrating the full stack
Spectro Cloud's PaletteAI is a platform built to manage exactly this kind of complexity — GPU-accelerated AI infrastructure from bare metal to model, across data center and edge environments.
The core design principle is bridging the gap between AI practitioners who need fast, self-service access to compute and infrastructure teams who need control, auditability, and security guardrails. PaletteAI handles that through a permission-driven self-service model: admins set the policies, and AI teams deploy within them without needing to file tickets.
For the AI Grid architecture specifically, PaletteAI acts as the end-to-end AI grid control plane. It integrates deeply with NVIDIA's software and hardware across every layer of the stack. To meet telco security requirements, PaletteAI uses Kairos, which enforces infrastructure immutability — meaning the OS and system state can't drift from a known-good configuration. Multi-tenancy is handled through integrations with Aviz and Netris, giving operators the isolation controls that enterprise and government customers demand.
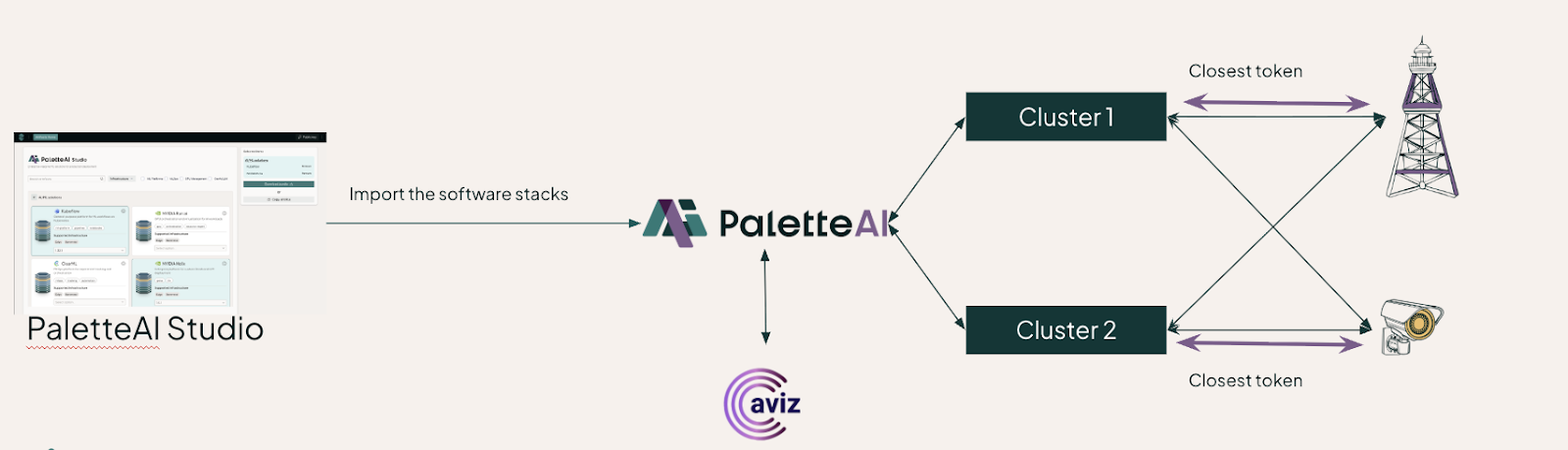
Figure 2. PaletteAI integration across the NVIDIA AI Grid stack.
PaletteAI Studio adds an application catalog layer on top of the control plane — a curated set of validated AI solutions that organizations can deploy with a few clicks rather than weeks of integration work.
For AI Grid deployments, that catalog includes NVIDIA Dynamo, Run.ai, and the AI Grid control plane, alongside open-source and partner tools like ClearML and LiteLLM. The result is that capabilities like semantic routing — routing inference requests to the model best suited to answer them, at the nearest available site — become accessible without requiring deep NVIDIA stack expertise to stand up.
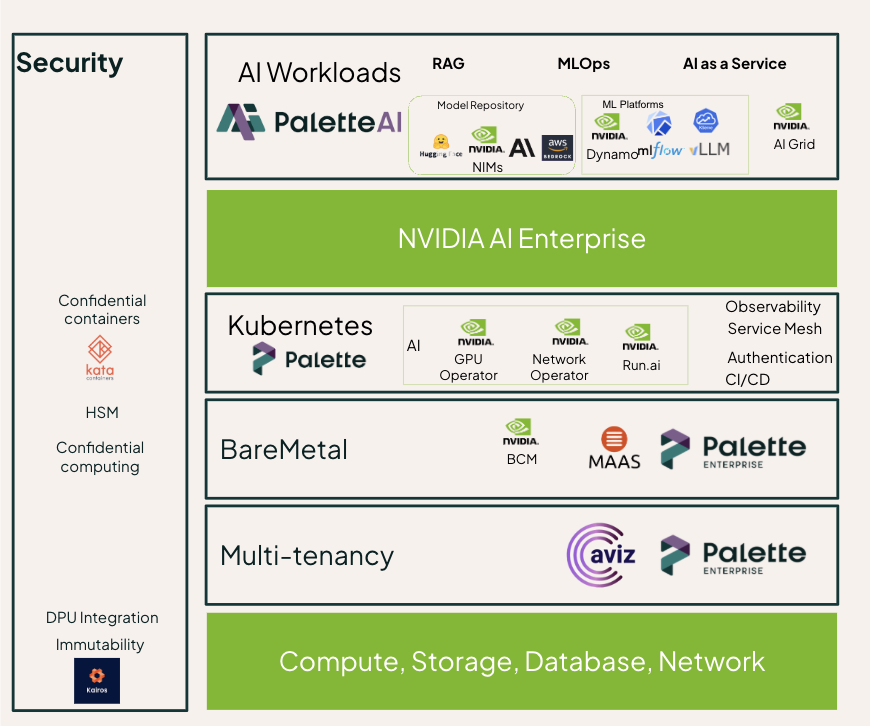
Figure 3. PaletteAI Studio application catalog for AI Grid deployments.
The intelligence grid is being built now
The telecom industry is in the middle of a genuine infrastructure pivot. The distributed assets that operators have spent decades building — edge sites, regional data centers, fiber backbones — are the exact physical substrate that a distributed AI Grid requires. The question is whether those assets get activated as an AI platform or whether that opportunity goes to someone else.
NVIDIA's AI Grid reference design gives telcos a concrete blueprint for that activation. It defines how to federate AI compute across sites, how to route workloads intelligently based on capability and proximity, and how to expose the whole thing as a monetizable service. The framework maps to a simple progression: create intelligence at the core, distribute it across the grid, and consume it at any node — for network optimization, enterprise AI services, edge inference, RAN workloads, or whatever comes next.
For that architecture to work in production at telco scale, the orchestration layer has to be robust enough to handle the operational reality: multiple sites, multiple tenants, immutable infrastructure, zero-trust security, and a software stack that keeps pace with NVIDIA's fast-moving hardware and software roadmap. That's what PaletteAI is built to provide — closing the gap between the reference design on paper and the running infrastructure in the field.
If you're evaluating how to build or extend your AI Grid deployment, we'd like to hear from you. Get in touch at spectrocloud.com/get-started.