

GPUs in Kubernetes and how to get them working
With the rapid advances in the use of AI/ML there has also been tremendous growth in the use of GPUs for supporting the intense amount of compute required to train models, process images, etc. In this tutorial we’ll walk through some considerations in getting a GPU up and running in Kubernetes.
Before we begin, let’s have a look at the components that enable a Kubernetes cluster to work with GPUs.
1. Extended Resources
Kubernetes, being a scheduling platform for compute workloads, uses linux cgroups and namespaces to provide granular access to the CPU, memory, and network resources.
Unlike with CPUs, Kubernetes doesn’t have the ability to schedule and manage GPU resources. As there are several hardware types such as GPUs, NICs, FPGAs, as well as multiple vendors, integration of all these options is not feasible in Kubernetes in-tree solutions. Instead, Kubernetes allows such resources to be handled as extended resources.
Device plugins, which we will encounter further in this blog, are responsible for handling and advertising these extended resources. The device plugin we use in this example handles nvidia GPU with resource name nvidia.com/gpu .
As GPUs are handled as extended resources, there are some limitations in Kubernetes for GPU workloads:
- GPUs are only supposed to be specified in the limits section, which means: (1) You can specify GPU limits without specifying requests because Kubernetes will use the limit as the request value by default, (2) You can specify GPU in both limits and requests but these two values must be equal, or (3) You cannot specify GPU requests without specifying limits.
- Containers (and Pods) do not share GPUs. There’s no overcommitting of GPUs.
- Each container can request one or more GPUs. It is not possible to request a fraction of a GPU.
2. Vendor Specific Device Driver Installer

Pods will need to have access to the device driver and other modules.
installs nvidia tools(nvidia-smi) and other shared-object files on the host, and Device Plugin later uses these mount paths in RequestAllocationResponse to kubelet. Device plugin using these tools discovers the devices and registers them.
A pod with these mount paths behaves as if it has a GPU libraries available to it.
Example installer manifest
3. Device Plugin
To enable a vendor device, Kubernetes allows device plugins. These plugins have to implement the gRPC interface.
The ListAndWatch interface allows device plugins to register devices and provide a list of available devices, which returns a stream of devices. If any device is not healthy it is removed from the available device list and new devices can be detected and made available.
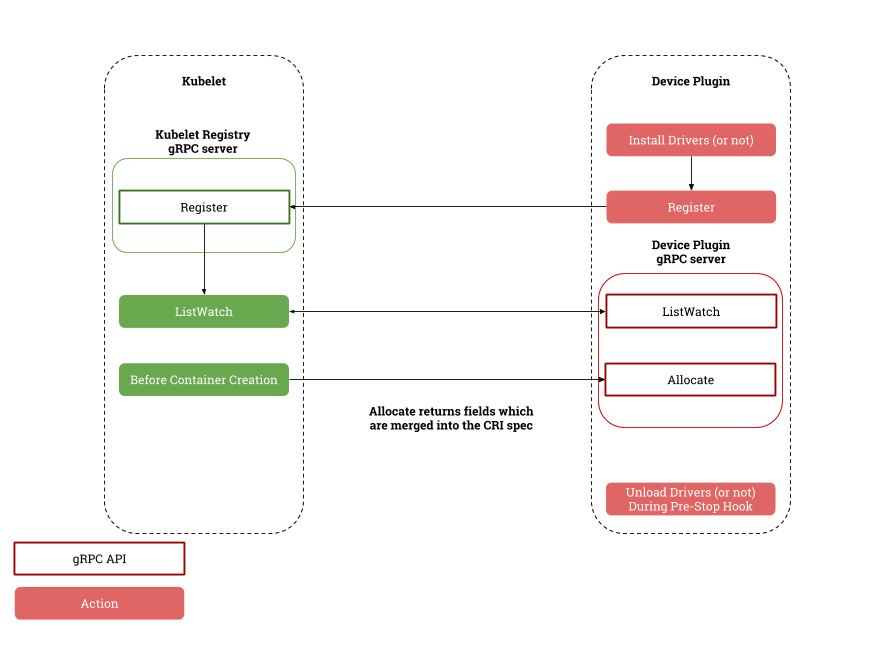
The Allocate interface helps device plugins provide kubelet with extra information for creating the pod. This allows the linux device driver directory to be exposed to container or special mount paths containing library and shared object files required for the pod workload to work, making kubelet think that it has the device available.

Device plugins can run device specific presetup code before pod creation.
Example device plugin manifest
Now that we know the ingredients let’s try to configure a Kubernetes cluster to work with GPUs. We have a prerequisite that the worker node with GPU has ubuntu 18.04 installed:
What happens when we schedule a GPU workload
Finally, here are the steps when we schedule a pod as mentioned above:
- Scheduler detects request for extended resource nvidia.com/gpu.
- The scheduler finds a node with GPU capacity and starts negotiating with device plugin for pod prerequisites using the gRPC call Allocate.
- The device plugin tells kubelet to mount the nvidia-device-driver location from host containing all the nvidia related binary files and shared libraries installed.
- The pod is created with specific mount point /usr/local/nvidia, and discovered devices to /dev in container so it thinks that it has a GPU available to it.

Hopefully this gives you a sense of how to deploy GPUs with Kubernetes. Of course, using Spectro Cloud can offload much of the infrastructure set up and management. Feel free to ask us any questions!
.webp)













.svg)

.webp)
