

As we all know, LLMs are trending like crazy and the hype is not unjustified. Tons of cool projects leveraging LLM-based text generation are emerging by the day — in fact, I wouldn’t be surprised if another awesome new tool was published during the time it took me to write this blog :)
For the unbeliever, I say that the hype is justified because these projects are not just gimmicks. They are unlocking real value, far beyond simply using ChatGPT to pump out blog posts 😉. For example, developers are boosting their productivity directly in their terminals via Warp AI, in their IDEs using IntelliCode, GitHub Copilot, CodeGPT (open source!) , and probably 300 other tools I have yet to encounter. Furthermore, the use cases for this technology extend far beyond code generation. LLM-based chat and Slack bots are emerging that can be trained on an organization’s internal documentation corpus. In particular, GPT4All from Nomic AI is a fantastic project to check out in the open source chat space.
However, the focus of this blog is yet another use case: how does an AI-based Site Reliability Engineer (SRE) running inside your Kubernetes cluster sound? Enter K8sGPT and the k8sgpt-operator.

Here’s an excerpt from their README:
is a tool for scanning your Kubernetes clusters, diagnosing, and triaging issues in simple English.
It has SRE experience codified into its analyzers and helps to pull out the most relevant information to enrich it with AI.
Sounds great, right? I certainly think so! If you want to get up and running as quickly as possible, or if you want access to the most powerful, commercialized models, you can install a K8sGPT server using Helm (without the K8sGPT operator) and leverage K8sGPT’s default AI backend: OpenAI.
But what if I told you that free, local (in-cluster) analysis was also a straightforward proposition?
That’s where LocalAI comes in. LocalAI is the brainchild of Ettore Di Giacinto (AKA mudler), creator of Kairos, another fast-growing open source project in the Kubernetes space. Here’s a brief excerpt from the LocalAI README:
LocalAI is a straightforward, drop-in replacement API compatible with OpenAI for local CPU inferencing, based on llama.cpp, gpt4all and ggml, including support GPT4ALL-J which is Apache 2.0 Licensed and can be used for commercial purposes.

Together, these two projects unlock serious SRE power. You can use commodity hardware and your data never leaves your cluster! I think the community adoption speaks for itself:
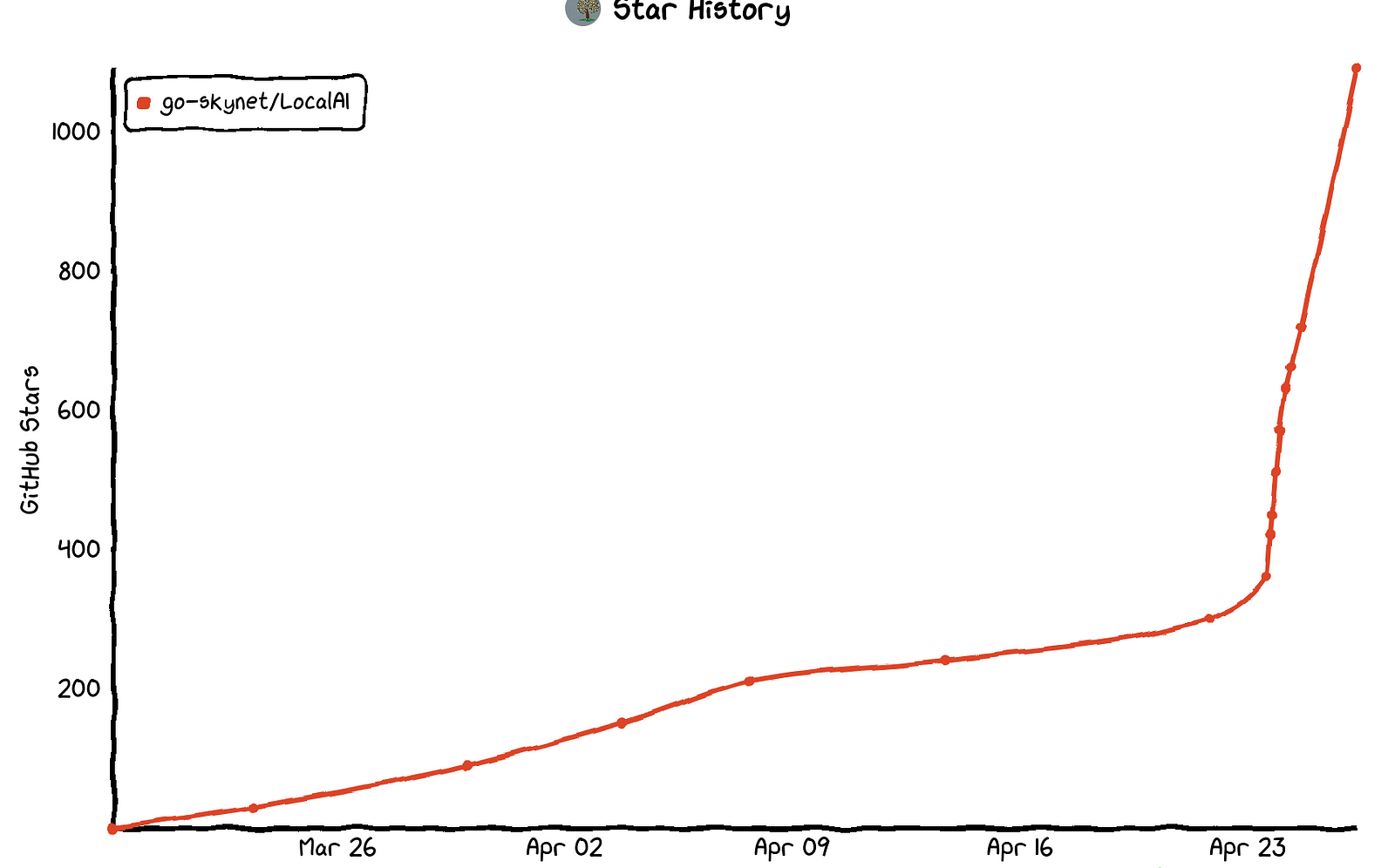
There are three phases to the setup:
- Install the LocalAI server
- Install the K8sGPT operator
- Create a K8sGPT custom resource to kickstart the SRE magic!
To get started, all you need is a Kubernetes cluster, Helm, and access to a model. See the LocalAI README for a brief overview of model compatibility and where to start looking. GPT4All is another good resource.
Ok… now that you’ve got a model in hand, let’s go!
Next, customize values.yaml:
And create a new Helm release:
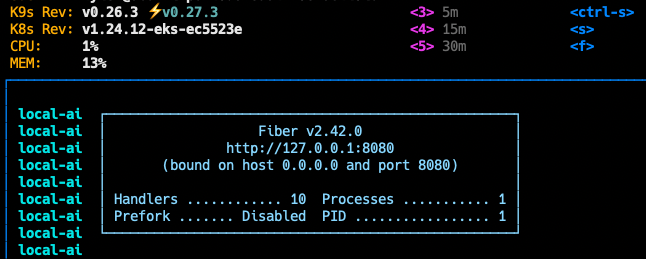
Assuming all is well, a local-ai Pod will be scheduled and you will see a pretty Fiber banner in the logs 🤗

Now for part two: installing the K8sGPT operator. We’ll use another fork here — apologies for that — hopefully this will be upstreamed soon and I can simplify the blog!
Next, install the K8sGPT operator CRDs and the operator itself:
Once that happens, you will see the K8sGPT operator Pod come online:


Next, manually edit the k8sgpt-operator-controller-manager Deployment and change the image used by the manager container to tylergillson/k8sgpt-operator:latest.
Cool. We’re almost there. One more step. To finish it off, we have to create a K8sGPT custom resource, which will trigger the K8sGPT operator to install a K8sGPT server and initiate the process of periodically querying the LocalAI backend to assess the state of your K8s cluster.
As soon as the K8sGPT CR hits your cluster, the K8sGPT operator will deploy K8sGPT and you should see some action in the LocalAI Pod’s logs.


Alright — that’s it! Sit back, relax, and allow the LocalAI model to hammer the CPUs on whatever K8s node was unlucky enough to be chosen by the scheduler 😅 I’m sort of kidding, but depending on the model you’ve chosen and the specs for your node(s), it is likely that you’ll start to see some CPU pressure. But that’s actually part of the magic! Gone are the days when we were forced to rely on expensive GPUs to perform this type of work.
I intentionally messed up the image used by the cert-manager-cainjector Deployment… and voilà!

One last thing before I wrap this up: if you thought that all of the steps involved to get this up and running were a bit onerous, I agree! So here’s my shameless Spectro Cloud plug. (Full disclosure, I work for Spectro Cloud).
Spectro Cloud Palette makes it trivial to model complex Kubernetes environments in a declarative manner using Cluster Profiles. Your Kubernetes clusters are continuously reconciled against their desired state using Cluster API and the orchestration happens at the target cluster —not on the management plane. This unique architecture is what allows Palette to easily scale to 1000’s of clusters across all major public clouds, private data centers (think VMware vSphere, OpenStack, MAAS), and even on edge devices.
But the magic doesn’t stop at the infrastructure level. Palette also supports a rich ecosystem of addon Packs, which encapsulate Helm charts and custom Kubernetes manifests; extending the declarative cluster configuration model to include whatever application workloads you wish to deploy on Kubernetes. Direct integration with external Helm and OCI registries is also supported.
So you can model your infrastructure layer (OS, Kubernetes, CNI, and CSI) as well as any addons you want, e.g., K8sGPT operator, LocalAI server, and Prometheus + Grafana for observability (O11Y) and Palette will take care of the heavy lifting.
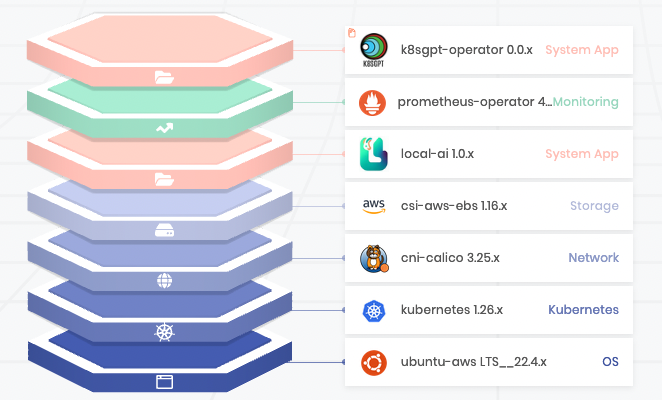
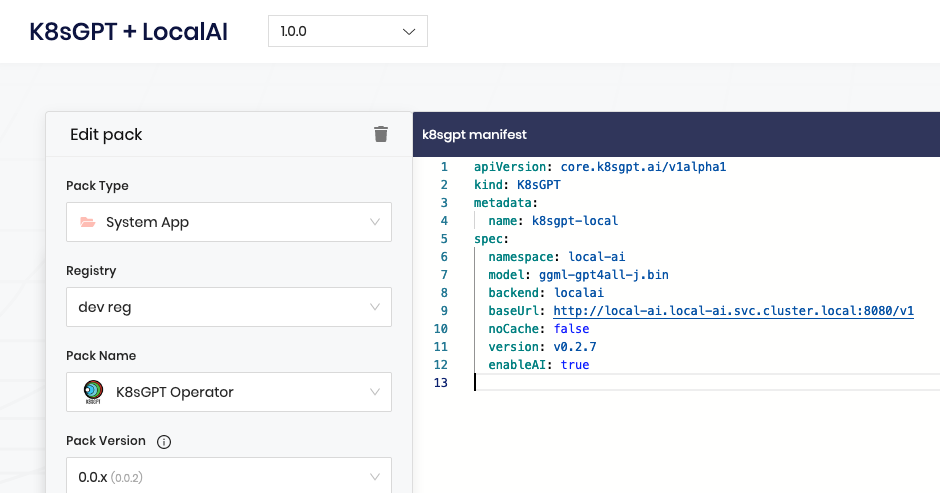
Now that I’ve modeled the application stack described in this blog as a Palette Cluster Profile, I can have it running in a matter of clicks! Of course the Palette API and Spectro Cloud Terraform provider are alternative options for those seeking automation.
Thanks so much for reading! I hope you learned something or at least found this interesting. The community is growing fast! Here are some links if you want to join in:
- Slack: https://k8sgpt.slack.com
- Twitter: https://twitter.com/k8sgpt
- Feel free to reach out to me directly at tyler@spectrocloud.com or check out the Spectro Cloud community Slack
.webp)













.svg)

.webp)
